
Gated Stereo: Joint Depth Estimation from Gated and Wide-Baseline Active Stereo Cues
-
Stefanie Walz
-
Mario Bijelic
-
Andrea Ramazzina
-
Amanpreet Walia
-
Fahim Mannan
-
Felix Heide
CVPR 2023 (Highlight)
We propose Gated Stereo, a high-resolution and long-range depth estimation technique that operates on active gated stereo images. Using active and high dynamic range passive captures, Gated Stereo exploits multi-view cues alongside time-of-flight intensity cues from active gating.
To this end, we propose a depth estimation method with a monocular and stereo depth prediction branch which are combined in a final fusion stage. Each block is supervised through a combination of supervised and gated self-supervision losses. To facilitate training and validation, we acquire a long-range synchronized gated stereo dataset for automotive scenarios. We find that the method achieves an improvement of more than 50% MAE compared to the next best RGB stereo method, and 74% MAE to existing monocular gated methods for distances up to 160m.
Paper
Gated Stereo: Joint Depth Estimation from Gated and Wide-Baseline Active Stereo Cues
Stefanie Walz, Mario Bijelic, Andrea Ramazzina, Fahim Mannan, Felix Heide
CVPR 2023
Experimental Results in Diverse Driving Conditions
In the following, qualitative results of the proposed Gated Stereo are compared to existing methods that use gated images (Gated2Gated), LiDAR+ monocular RGB images (Sparse2Dense) and stereo RGB images (RAFT-Stereo) as input. Gated2Gated uses the same three active gated slices as our proposed method, but without the passive HDR-like input images. Sparse2Dense relies on sparse LiDAR data and a monocular RGB image as input and upsamples the LiDAR depth with monocular texture cues. RAFT-Stereo (RGB) is the next best stereo depth estimation method with RGB data as input.
Nighttime Downtown Environment |
Nighttime Suburban Environment |
Daytime Downtown Environment |
Daytime Suburban Environment |
Depth from Gated Stereo
To achieve the results from above, we proposed a model architecture that is composed of two monocular ($f^m_z$), one stereo ($f^s_z$), and two fusion ($f^r_z$) networks with shared weight. The fusion network combines the output of the monocular and stereo networks to obtain the final depth image for each view. Both stereo and monocular networks use active and passive slices as input, with the stereo network using the passive slices as context and relies on a decoder ($f_{\Lambda\alpha}$) for albedo and ambient estimation for gated reconstruction. The loss terms are applied to the appropriate pixels using masks that are estimated from the inputs and outputs of the networks.

Illuminator View ConsistencyIn the proposed gated stereo setup, we can enforce an additional depth consistency from the illuminator field of view. In this virtual camera view no shadows are visible as illustrated in the Figure below. This effectively makes the regions that are visible to the two cameras and the illuminator consistent. We use the gated consistency mask $M_{g}$ to supervise only regions that are illuminated by the laser and project the gated views $I_{l,r}$ into the laser field of view $I_{il|r,l}$, resulting in the loss, $$\mathcal{L}_{illum} = \mathcal{L}_p(M_{g} \odot I_{il|l}, M_{g} \odot I_{il|r}) $$ |
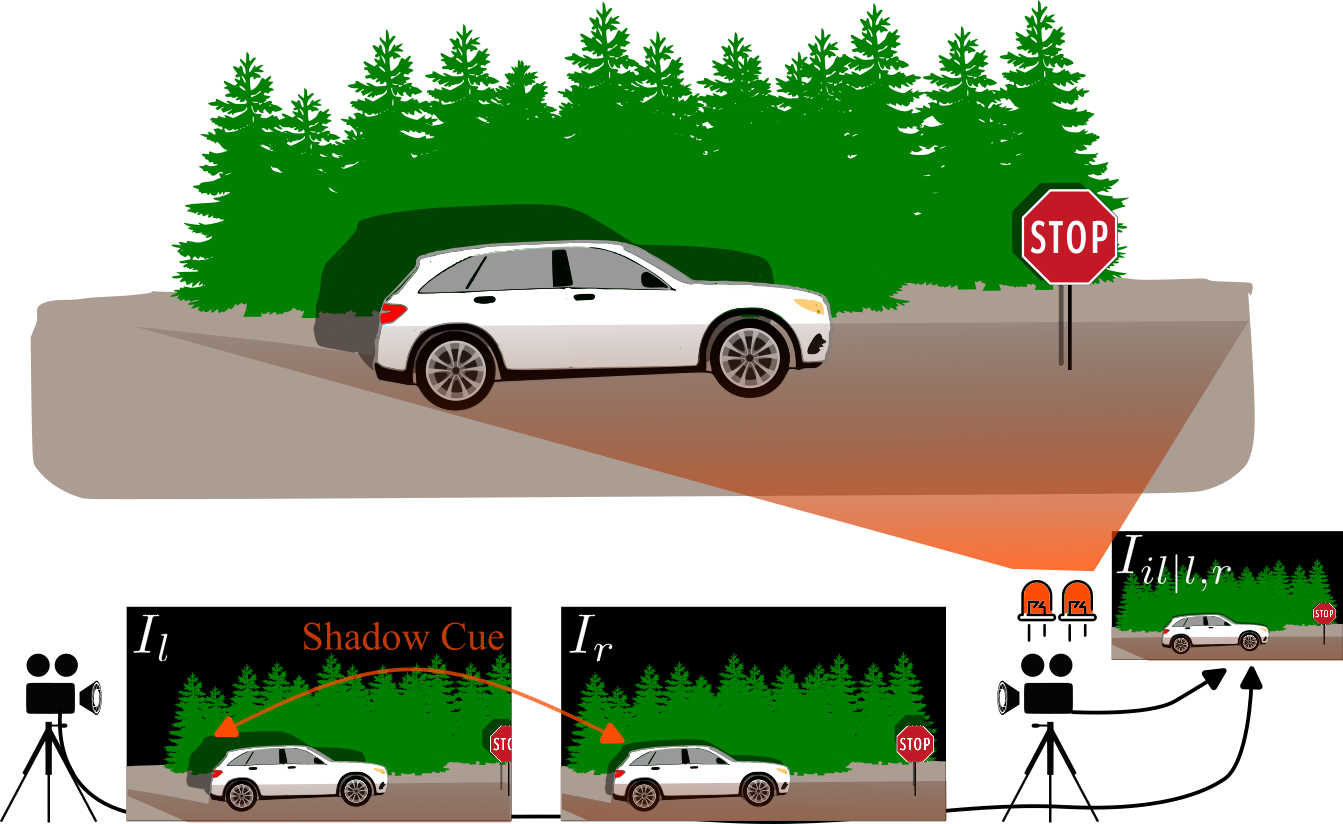 |
Ambient Image ConsistencyThe ambient illuminance in a scene can vary by 14 orders of magnitude, inside a dark tunnel with bright sun at a tunnel exit, all in the same scene. To tackle this extreme dynamic range, we reconstruct the ambient $\Lambda^{k_0}$ in the scene from the short exposure slice $\mu_k$, and sample $\Lambda^{HDR}$ from the HDR passive captures $I^4, I^5$. Then, novel scene images $\hat{I}_v^k$ can be expressed as,$$\Lambda^{HDR}_v = \mu_s(I^4_v+I^5_v-D_v^4-D_v^5)/(\mu_4+\mu_5), $$$$\Lambda^{k_0}_v = \mu_k(I^4_v+I^5_v-D_v^4-D_v^5)/(\mu_4+\mu_5), $$$$ \hat{I}_v^k = \text{clip}\left(I_v^k – \Lambda^{k_0}_v + \Lambda^{HDR}_v,0,2^{10}\right),$$with $\mu_s$ uniformly sampled in the interval from $[0.5\mu_k, 1.5\mu_k]$. We supervise the network by enforcing the depth to be consistent across different ambient illumination levels. |
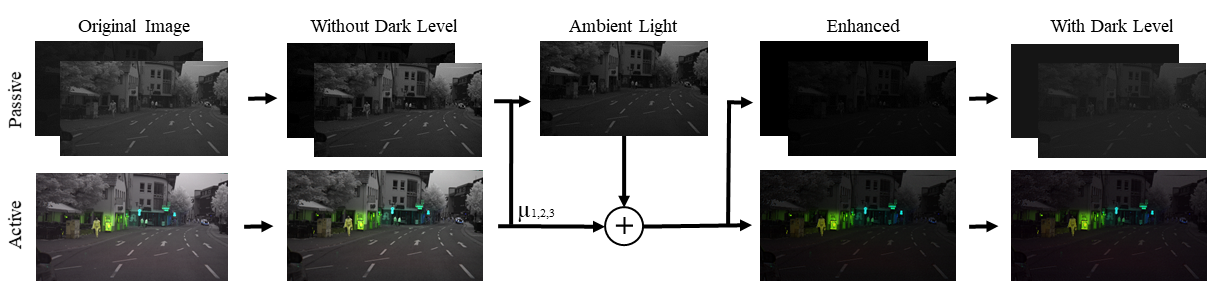
|

Gated Stereo Dataset
To train and evaluate the proposed Gated Stereo method, we acquired a long-range gated stereo dataset during a data collection campaign covering more than one thousand kilometers of driving in Southern Germany. We have equipped a testing vehicle with a long-range LiDAR system (Velodyne VLS128) with a range of up to 200m, an automotive RGB stereo camera (OnSemi AR0230 sensor) and a NIR gated stereo camera setup (BrightWayVision) with synchronization. The sensor setup is shown below with all sensors mounted in a portable sensor cube, except for the LiDAR sensor. The RGB stereo camera has a resolution of 1920×1080 pixels and runs at 30 Hz capturing 12bit HDR images. The gated camera provides 10 bit images with a resolution of 1280×720 at a framerate of 120 Hz, which we split up into three slices plus two HDR-like additional ambient captures without active illumination. The mounted reference LiDAR system is running with 10 Hz and yields 128 lines. All sensors are calibrated and time-synchronized. The dataset contains 107348 samples in day, nighttime, and varying weather conditions. After sub-selection for scenario diversity, we split the dataset into 54320 samples for training, 728 samples for validation and, 2463 samples for testing. For access to the dataset, please visit our dataset webpage, where the Gated Stereo Dataset is included as part of the Long Range Stereo dataset.
Related Publications
[1] Amanpreet Walia, Stefanie Walz, Mario Bijelic, Fahim Mannan, Frank Julca-Aguilar, Michael Langer, Werner Ritter and Felix Heide. Gated2Gated: Self-Supervised Depth Estimation from Gated Images. The IEEE International Conference on Computer Vision (CVPR), 2022.
[2] Frank Julca-Aguilar, Jason Taylor, Mario Bijelic, Fahim Mannan, Ethan Tseng, and Felix Heide. Gated3D: Monocular 3D Object Detection From Temporal Illumination Cues. The IEEE International Conference on Computer Vision, 2021.
[3] Tobias Gruber, Frank D. Julca-Aguilar, Mario Bijelic, Werner Ritter, Klaus Dietmayer, and Felix Heide. Gated2depth: Real-time dense lidar from gated images. The IEEE International Conference on Computer Vision, 2019
[4] Lahav Lipson, Zachary Teed and Jia Deng. RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching. The International Conference on 3D Vision (3DV), 2021.
[5] Fangchang Ma and Sertac Karaman. Sparse-to-dense: Depth prediction from sparse depth samples and a single image. The IEEE international conference on robotics and automation (ICRA), 2018.