
Gated3D: Monocular 3D Object Detection From Temporal Illumination Cues
- Frank Julca-Aguilar
-
Jason Taylor
- Mario Bijelic
- Fahim Mannan
- Ethan Tseng
- Felix Heide
ICCV 2021

We propose a novel 3D object detection method, "Gated3D", which uses a flood-illuminated gated camera. The high resolution of gated images enables semantic understanding at long ranges. In the figure, our gated slices are color-coded with red for slice 1, green for slice 2 and blue for slice 3. We evaluate Gated3D on real data collected with a Velodyne HDL64-S3D scanning lidar as reference, as seen in the overlay on the right.
Today's state-of-the-art methods for 3D object detection are based on lidar, stereo, or monocular cameras. Lidar-based methods achieve the best accuracy, but have a large footprint, high cost, and mechanically-limited angular sampling rates, resulting in low spatial resolution at long ranges. Recent approaches using low-cost monocular or stereo cameras promise to overcome these limitations but struggle in low-light or low-contrast regions as they rely on passive CMOS sensors. In this work, we propose a novel 3D object detection modality that exploits temporal illumination cues from a low-cost monocular gated imager. We introduce a novel deep detection architecture, Gated3D, that is tailored to temporal illumination cues in gated images. This modality allows us to exploit mature 2D object feature extractors that guide the 3D predictions through a frustum segment estimation. We assess the proposed method experimentally on a 3D detection dataset that includes gated images captured over 10,000 km of driving data. We validate that our method outperforms state-of-the-art monocular and stereo methods.
Paper
Frank Julca-Aguilar, Jason Taylor, Mario Bijelic, Fahim Mannan, Ethan Tseng, Felix Heide
Gated3D: Monocular 3D Object Detection From Temporal Illumination Cues
ICCV 2021
Video Summary
Method description
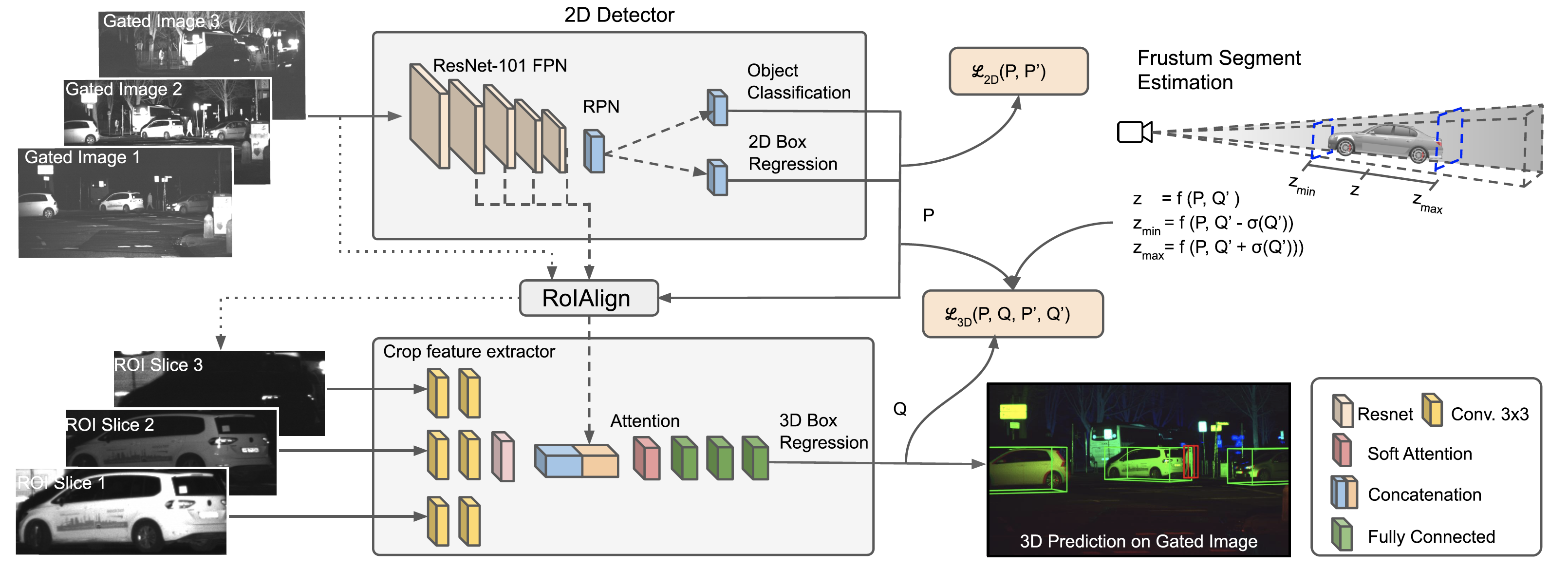
Network Architecture
To detect objects and predict their 3D location, dimension and orientation our proposed network requires three gated slices with overlapping illumination fields. Therefore our network first employs a 2D detection network to detect ROIs. The resulting 2D boxes are used to crop regions from both the backbone network and input gated slices. Secondly, we apply a dedicated 3D network, which estimates object 3D location by using a frustum segment computed from the 2D boxes and 3D statistics of the training data. The network processes the gated slices separately, then fuses the resulting features with the backbone features and estimates the 3D bounding box parameters.
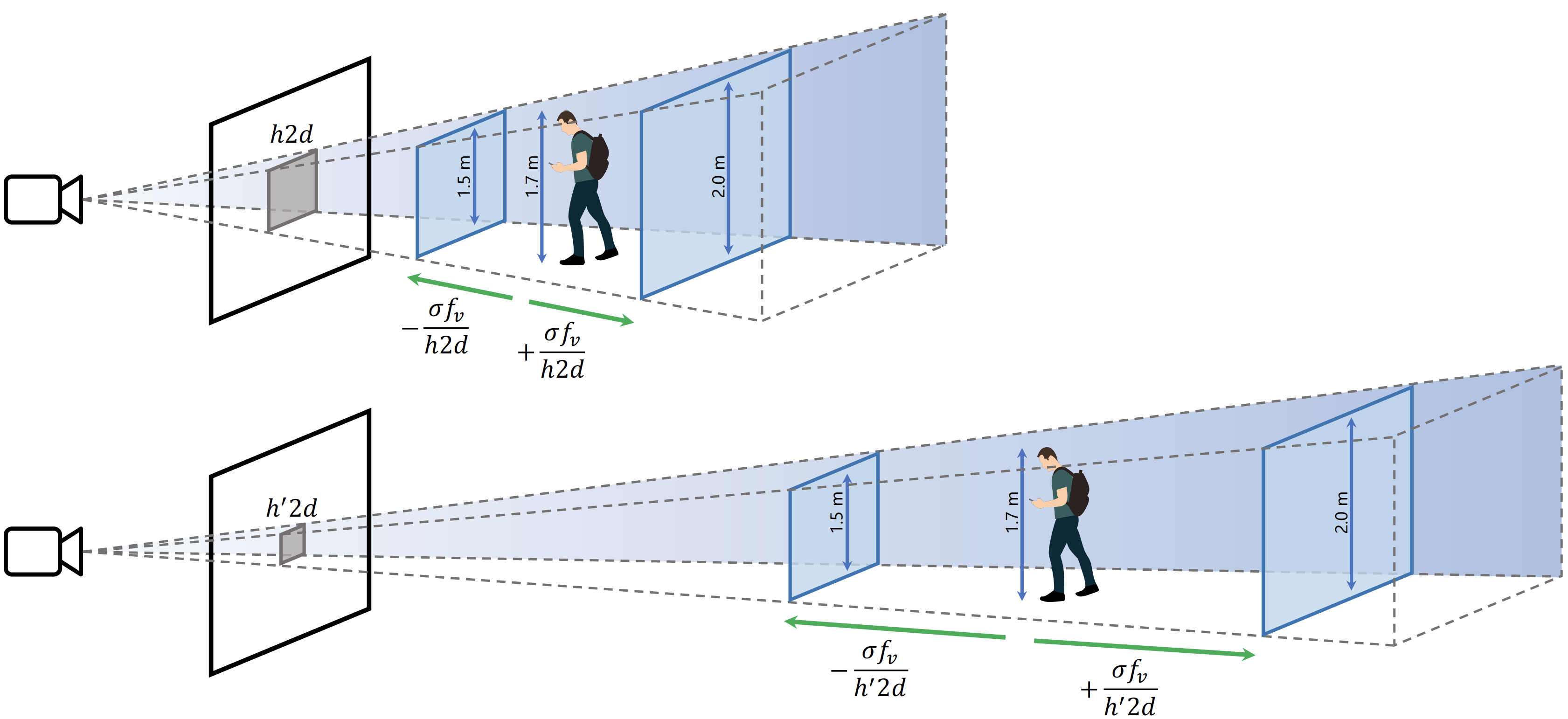
Estimation of object distance
We are able to estimate the object distance from the viewing frustum and the object height, its projected height and the vertical focal length. This is beneficial as there is an infinite number of 3D cuboids that can project to a given bounding box. In detail we assume that the object height h follows a gaussian distribution and use it to constrain the frustum depth d. For more information please see the publication.

Test Setup
To record the dataset used for training and evaluating the proposed method we used the research vehicle on the left hand side. The dataset also includes corresponding lidar point clouds and stereo image pairs, see right table for sensor parameters. The stereo camera is located at approximately the same position of the gated camera in order to ensure a similar viewpoint.

Results

Qualitative Results
Qualitative comparisons on the test dataset. Bounding boxes from the proposed method are tighter and more accurate than the baseline methods. This is seen in the second image with the other methods showing large errors in pedestrian bounding box heights. The BEV lidar overlays show our method offers more accurate depth and orientation than the baselines. For example, the car in the intersection of the fourth image has a 90 degree orientation error in the pseudo-lidar and stereo baselines, and is missed in the monocular baseline. The advantages of our method are most noticeable for pedestrians, as cars are easier for other methods due to being large and specular (please zoom in for details).
Supplementary Videos - Long Test Drives
Related Work
[1] Tobias Gruber, Frank D. Julca-Aguilar, Mario Bijelic, Werner Ritter, Klaus Dietmayer, and Felix Heide. Gated2depth: Real-time dense lidar from gated images. The IEEE International Conference on Computer Vision, 2019.
[2] Bijelic, Mario and Gruber, Tobias and Mannan, Fahim and Kraus, Florian and Ritter, Werner and Dietmayer, Klaus and Heide, Felix. Seeing Through Fog Without Seeing Fog: Deep Multimodal Sensor Fusion in Unseen Adverse Weather. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.