
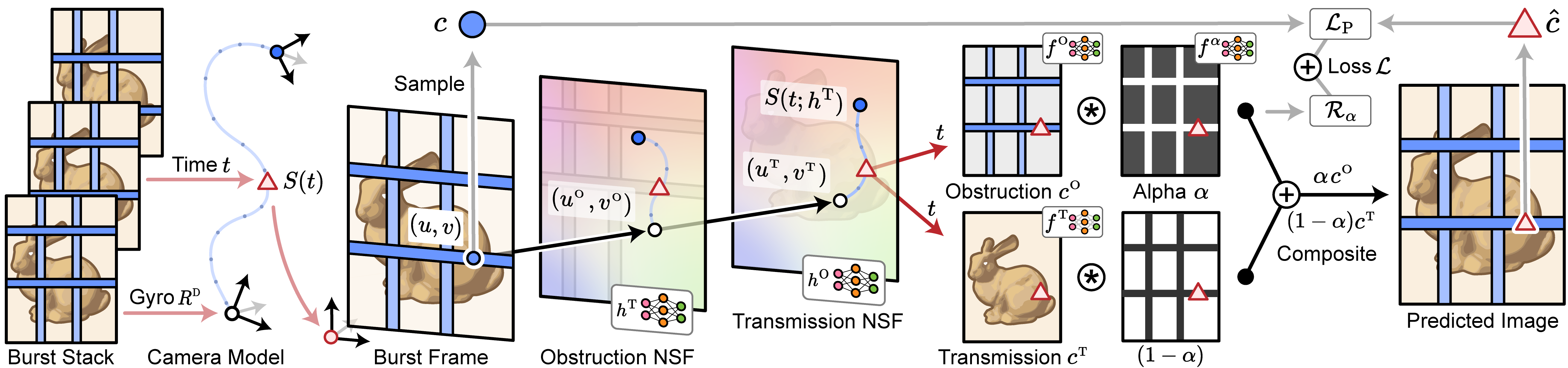
Neural Spline Fields for Burst Image Fusion and Layer Separation
With tiny optical hardware, and tinier sensors, burst imaging pipelines have proven essential to high-quality cellphone photography. These pipelines acquire a sequence of frames in rapid succession, and align and merge the noisy image stack computationally to produce a high-quality photo. While successful, conventional burst approaches only produce a single photo as an output, mixing together parts of the scene which the user wants to see — like the beautiful stone-work on a chapel door — with parts the user may not want — the fence blocking their view of the chapel.
In this work, we use burst image stacks for layer separation. We represent a burst of images with a two-layer alpha-composited image plus flow model constructed with neural spline fields – networks trained to map input coordinates to spline control points. We directly input an unstabilized burst of full-resolution 12-megapixel RAW images into our model with no post-processing. Through test-time optimization it jointly fuses these frames into a high-fidelity reconstruction, while, with the help of parallax from natural hand tremor, jointly separating the scene into transmission and obstruction layers. By discarding this obstruction layer, we demonstrate how we can remove occlusions, suppress reflections, and even erase photographer-cast shadows; outperforming learned single-image and multi-view obstruction removal methods.
Neural Spline Fields
Rather than represent flow as a 3D volume — a function of x,y and time — we propose neural spline fields (NSFs) as a compact alternative flow model. These NSFs are coordinate networks which map an input x,y point to a vector of spline control points. These are then evaluated at the sample time just like an ordinary spline to produce flow estimates, meaning the temporal behavior of the NSF outputs are directly controlled by its chosen spline parametrization. We find this flow representation, without any regularization, fits to produce temporally consistent flow estimates that agrees with a conventional optical flow reference.


Multi-Resolution Controllability
We leverage the strong spatial controls provided by multi-resolution hash encodings to allocate spatial complexity only to where it is needed in our image formation model. Providing networks such as those responsible for the transmission image high-resolution grid encodings to perform detailed reconstruction of the input 12-megapixel image data, and restricting flow models to low-resolution grids to ensure spatial consistency.
A Lot of Obstruction Removal from a Little Motion
Fit to a two-second burst of images, our model uses the motion from natural hand tremor to separate content into obstruction and transmission layers. Shown in the training videos above and below, we can use this layer separation to remove occlusions and suppress reflections, and reveal unseen content in both layers! Hard reflections, out-of-focus fences, or even occluders that cover more of the scene than they let through; our approach can fit a wide range of obstructions and environments to produce high-quality layer separation results. All with a training time of only 3 minutes on a single RTX 4090.
Beyond Windows and Fences
We design our two-layer image-plus-flow model to be as versatile as possible, able to perform tasks ranging from classic align-and-merge image denoising to photographer-cast shadow removal. Any scene which is the product of multiple motion models — whether that motion be from the subject, the camera, or the lights themselves — has the potential to be separated into multiple image layers.
Related Publications
[1] Ilya Chugunov, Yuxuan Zhang, and Felix Heide. Shakes on a Plane: Unsupervised Depth Estimation from Unstabilized Photography. CVPR 2023
[2] Ilya Chugunov, Yuxuan Zhang, Zhihao Xia, Cecilia Zhang, Jiawen Chen, and Felix Heide. The Implicit Values of a Good Hand Shake: Handheld Multi-Frame Neural Depth Refinement. CVPR 2022 (Oral)