
Shakes on a Plane: Unsupervised Depth Estimation from Unstabilized Photography
CVPR 2023
Modern mobile burst photography pipelines capture and merge a short sequence of frames to recover an enhanced image, but often disregard the 3D nature of the scene they capture, treating pixel motion between images as a 2D aggregation problem. We show that in a “long-burst”, forty-two 12-megapixel RAW frames captured in a two-second sequence, there is enough parallax information from natural hand tremor alone to recover high-quality scene depth.
We devise a test-time optimization approach that fits a neural RGB-D representation to long-burst data and simultaneously estimates scene depth and camera motion. Our plane plus depth model is trained end-to-end, and performs coarse-to-fine refinement by controlling which multi-resolution volume features the network has access to at what time during training. We demonstrate accurate depth reconstruction with no additional hardware or separate data pre-processing and pose-estimation steps.
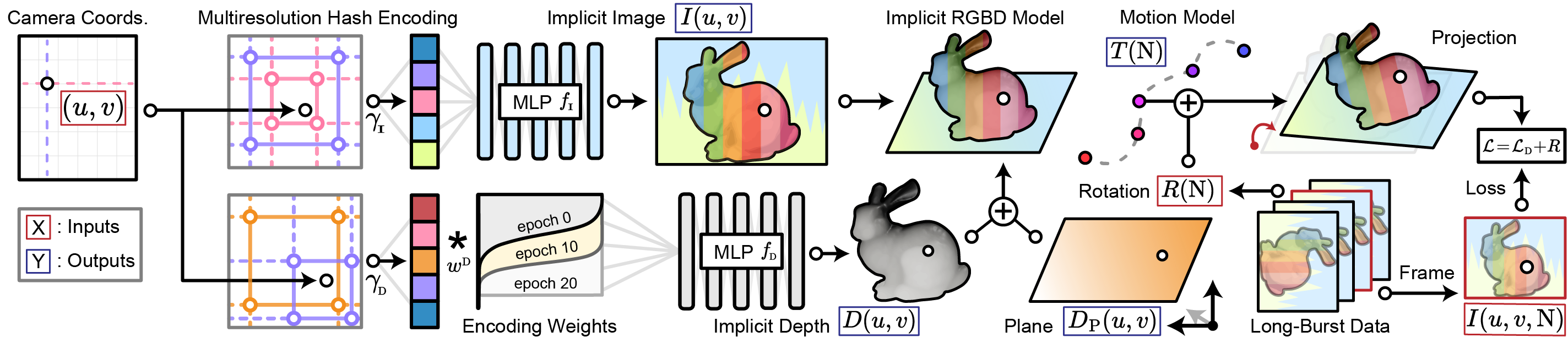
A Neural RGB-(Plane plus D) Model
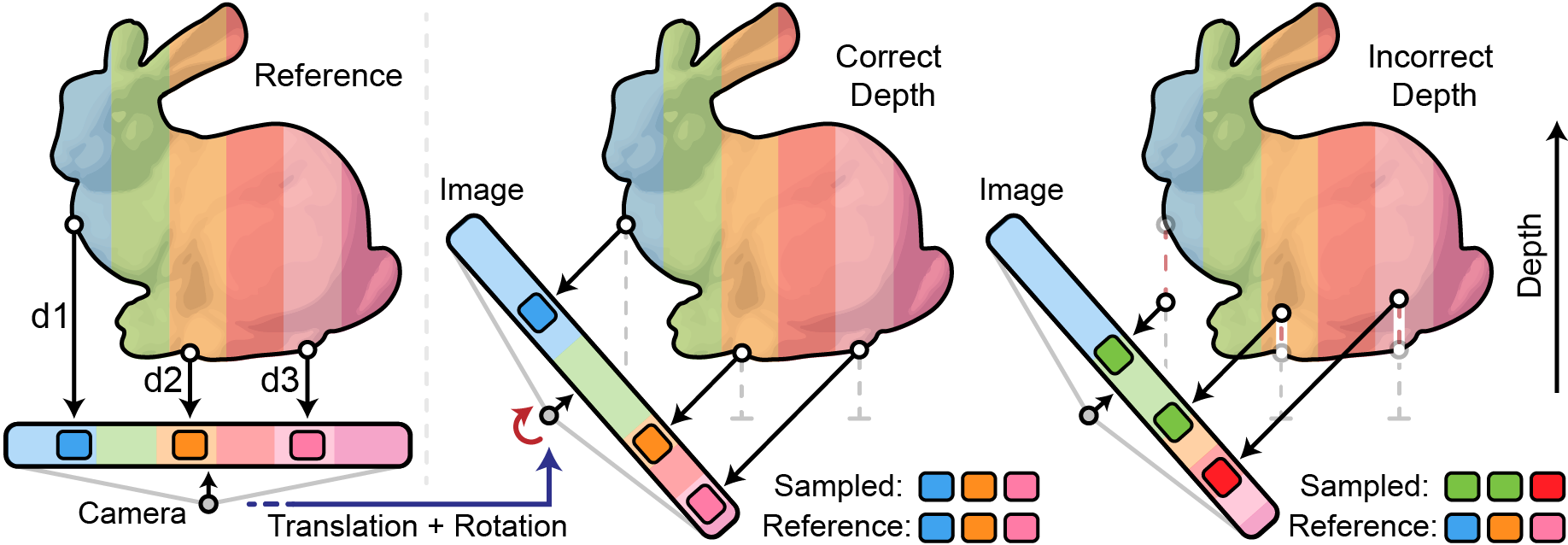
Rather than break depth and pose estimation into disjoint steps, we propose a single neural RGB-D model fit directly to unstabilized long-burst images. Trained end-to-end, we jointly learn high-quality depth and high-precision camera poses with no labeled training data, all from maximizing photometric consistency between our model’s outputs and RAW image data. Our plane plus depth model allows us to gracefully handle low-texture background content with weak parallax cues, pulling these areas away from spurious depth estimates and towards a simple linear solution.
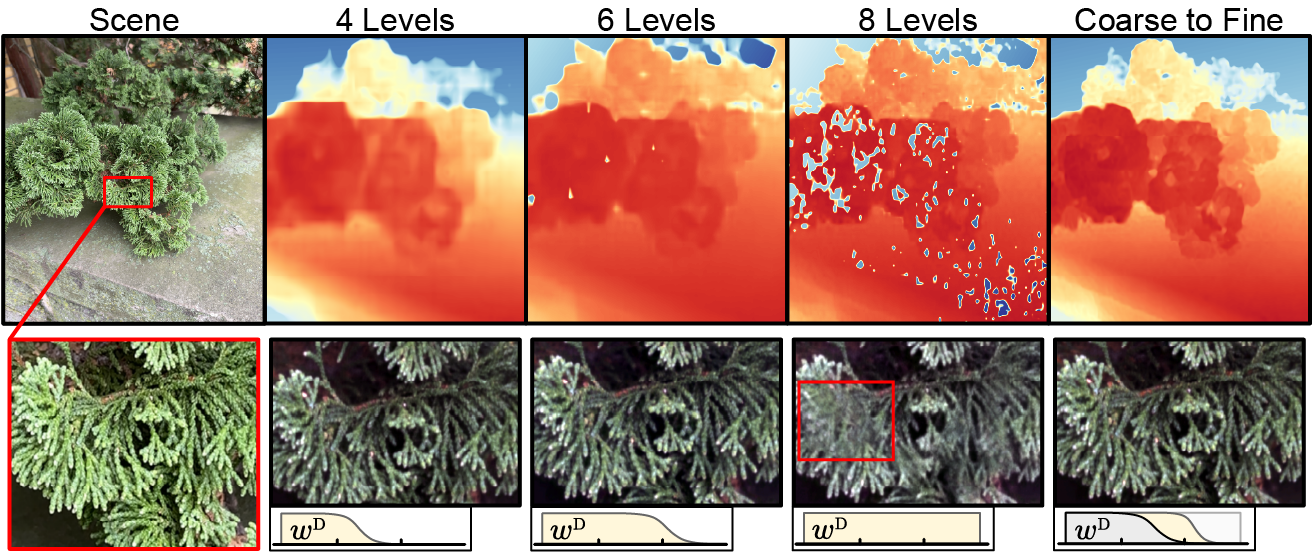
Coarse-to-Fine Training
By applying a mask to the positional encoding weights, we can control which levels of the multi-resolution hash encoding the network has access to during which training epochs. As this positional encoding in turn controls the size of reconstructed depth features, we can effectively perform coarse-to-fine reconstruction by sweeping through the encoding levels; maximizing final reconstruction detail while minimizing accumulated noise from early training epochs.
Learned RGB as an Optimization Vehicle
During training we not only learn an implicit model of depth, but also an implicit model of the reference image from which we calculate photometric loss. This allows our method to traverse intermediate image representations, starting with noisy and misaligned features which are refined during training. In turn, this lowers the burden on the depth and camera motion models during early training stages, as they can first focus on aligning these coarse features before jointly learning to reconstruct more fine-grain image content.
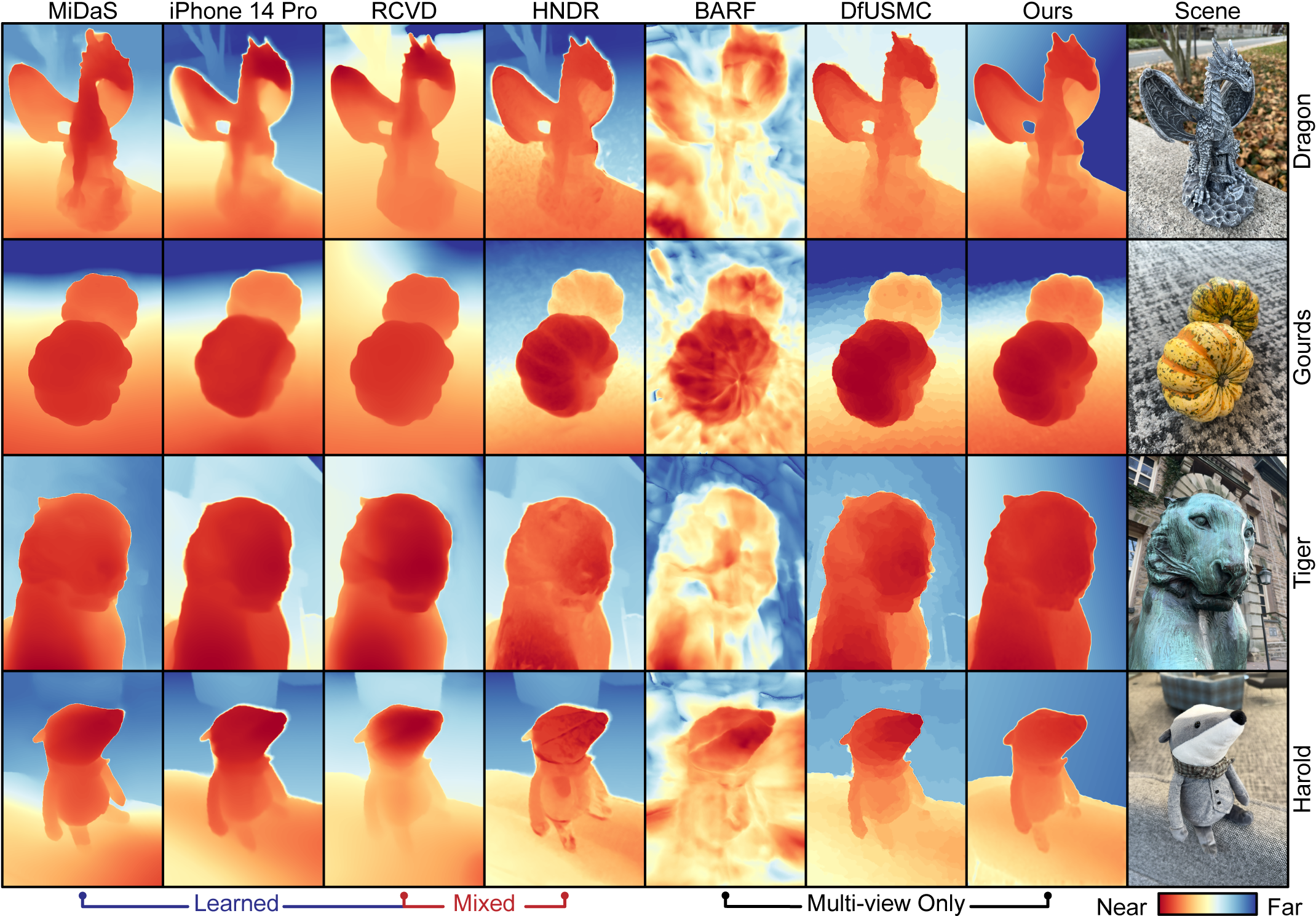
Reconstruction Results
Tested on a variety of both indoor and outdoor scenes, our unsupervised approach outperforms comparable purely multi-view methods, and even produces results competitive with learned monocular methods. All without additional hardware requirements (e.g. LiDAR sensors); only 12-megapixel images and gyroscope measurements, available on almost all modern cellphones.

Comparison to Structured Light Scans
To further validate the accuracy of our approach, we acquired a set of high-accuracy structured light depth scans for a set of target objects. From the mesh projections we can clearly see how our reconstructions are highly consistent with true object geometries, and conversely how the learned monocular method hallucinates inconsistent internal object structure, for example tearing the wings of the Dragon from its torso.
Applications to Image and Depth Matting
While low-texture and distant scene content does not produce sufficient parallax information for meaningful multi-view depth reconstruction, our model’s plane plus offset depth decomposition allows us to easily and accurately segment these regions. We can then super-impose the depth and image content for which we do have reliable parallax cues onto a new scene, with background depth hallucinated with the help of a learned single-image method. In this way we can leverage multi-view information where we have it, and learned priors where we don’t.
Related Publications
[1] Ilya Chugunov, Yuxuan Zhang, Zhihao Xia, Cecilia Zhang, Jiawen Chen, and Felix Heide. The Implicit Values of a Good Hand Shake: Handheld Multi-Frame Neural Depth Refinement. CVPR 2022 (Oral)