
Handheld Multi-Frame Neural Depth Refinement
CVPR 2022 (Oral)
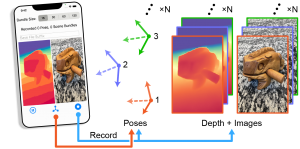
Modern smartphones can stream multi-megapixel RGB images, high-quality 3D pose information, and low-resolution depth estimates at 60 frames per second. In tandem, a phone photographer’s hand is never perfectly still, and natural hand-shake provides us with dense micro-baseline stereo depth cues during viewfinding (the seconds between pointing the phone at an object and hitting the capture button).
In this work, we explore how to combine all these data streams in an implicit learned model and demonstrate high-fidelty depth recovery for tabletop (<50cm distance) objects from a single snapshot. We emphasize ‘point-and-shoot’ depth reconstruction, and require no additional hardware, artificial hand motion, or user interaction beyond the press of a button.
![]()
LiDAR Depth:

Proposed:
(In Browser: Click and Drag to Rotate, Scroll to Zoom)
The Implicit Values of A Good Hand Shake :
Handheld Multi-Frame Neural Depth Refinement
Ilya Chugunov, Yuxuan Zhang, Zhihao Xia, Cecilia Zhang, Jiawen Chen, Felix Heide
CVPR 2022 (Oral)
Data Collection
We developed an iOS app to record bundles of synchronized image, pose, and depth frames. The user simply selects a bundle size (from 15 to 120 frames, or equivalently 0.25 to 2 seconds of recording), focusses the shot on a target object or scene with the viewfinder, and presses a button to capture the snapshot.
Micro-baseline Parallax
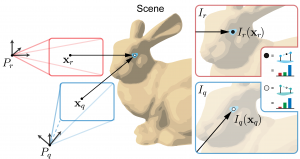
Natural hand tremor causes micro-misalignments between frames, and about 5mm of effective stereo baseline between the farthest frames in a recorded bundle. Even at close distances, such a small baseline leads to only pixels (or fractions of pixels) in disparity between aligned points in adjacent frames. To extract meaningful depth information we thus need to method that can use more than just a pair of images.
The Implicit Values of a Hand-Shake
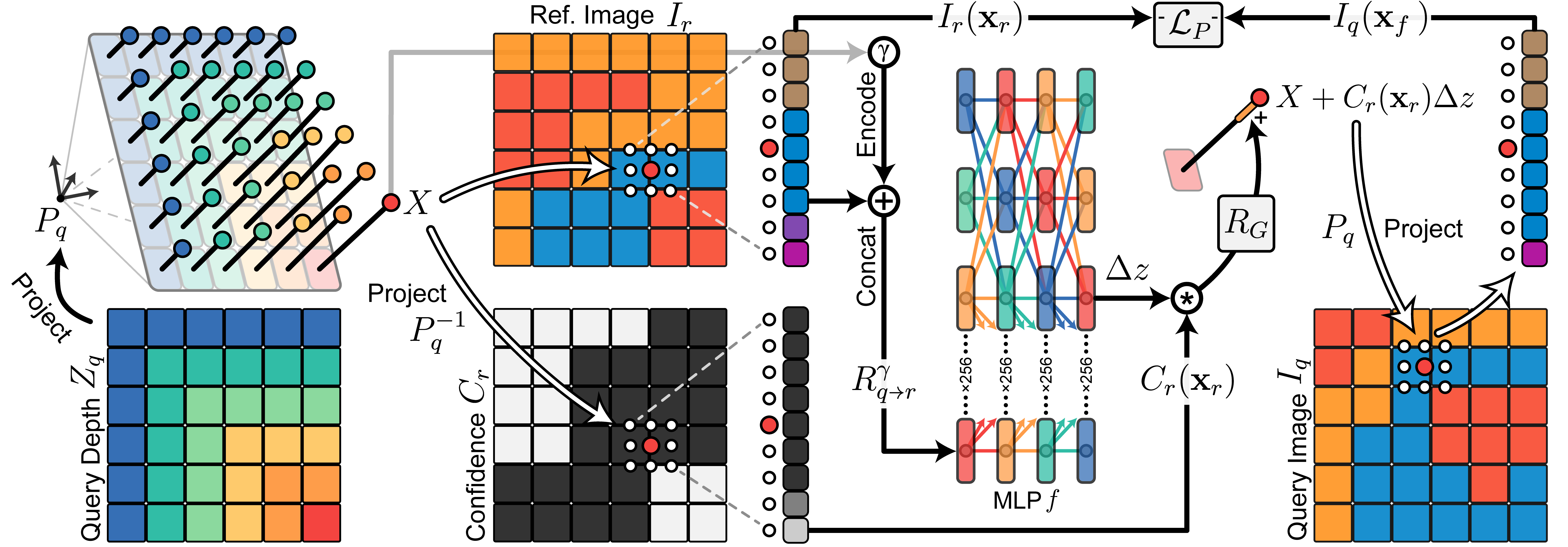
Rather than try to directly calculate disparity between frames, we see the entirety of the recorded bundle as a series of continuous samples in 3D/RGB space. Initializing the reconstruction at the course LiDAR-guided depth estimates from the phone, we repeatedly query a multi-layer perceptron to provide per-sample depth offsets which minimize the overall photometric error in the bundle. During training we essentially generate an implicit continuous depth field such that when samples are projected from one 3D coordinate frame to another (via the collected high-accuracy phone poses), they sample color-consistent points in the corresponding image frames.
Castle:
Thinker:
Rocks:
Gourd:
(In Browser: Click and Drag to Rotate, Scroll to Zoom)
Results
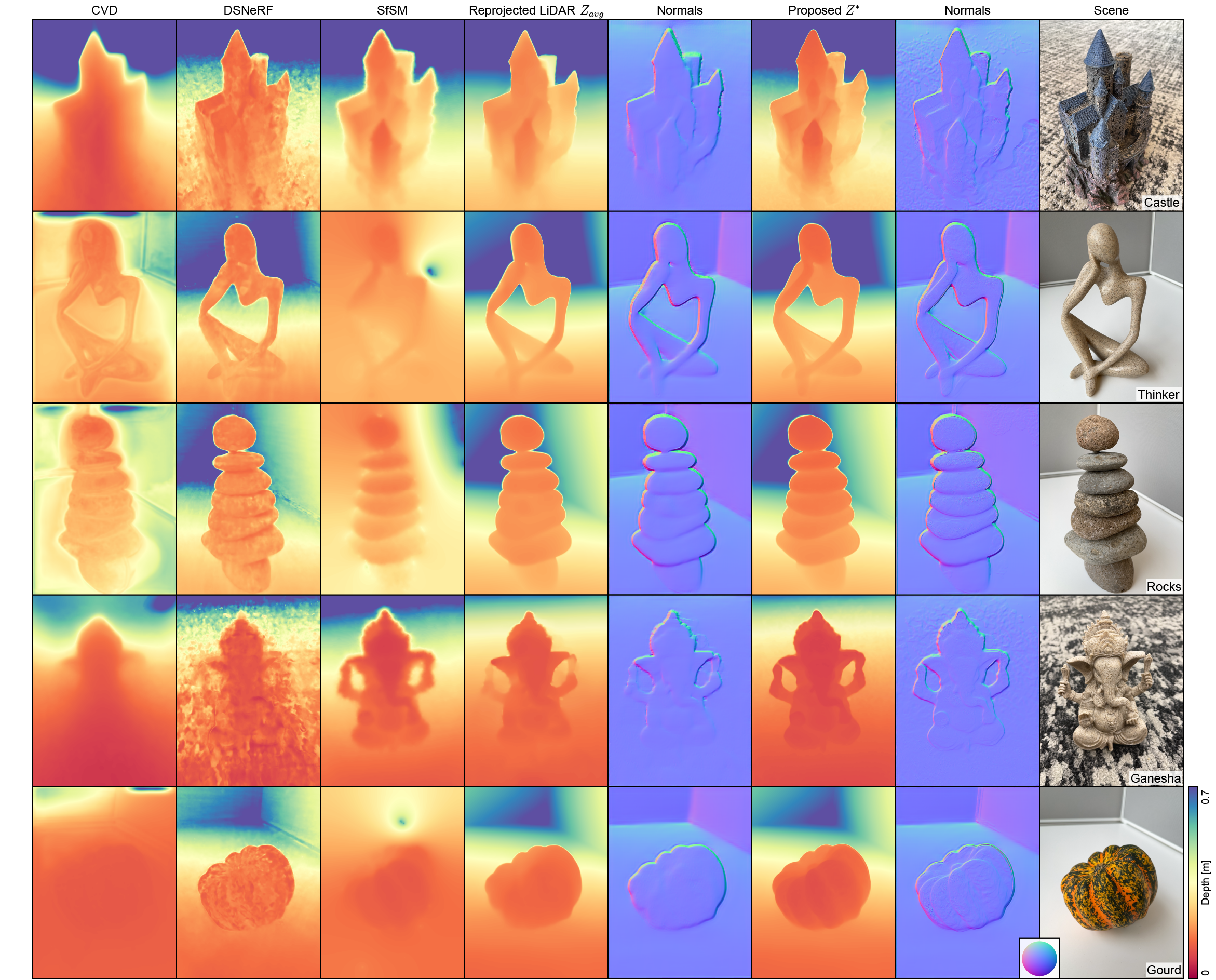
Where COLMAP fails to converge, and other methods struggle to produce consistent depth outputs, our method recovers 3D features completely missing in the underlying LiDAR-guided depth data. Visually ambiguous regions with difficult texture cues, such as the castle‘s spires and the gourd‘s curves, are successfully reconstructed by our method while appearing flattened or smoothed in the LiDAR-guided measurements. Textureless regions, such as the plain gray background, provide little-to-no photometric guidance and are thus left unperturbed at their plane-fit LiDAR depth solutions. In this way we can add detail to the reconstruction of highly textured close-range objects without introducing undue noise to other parts of the scene.