
Neural Light Spheres for Implicit Image Stitching and View Synthesis
SIGGRAPH Asia 2024
Challenging to capture, and challenging to display on a cellphone screen, the panorama paradoxically remains both a staple and underused feature of modern mobile camera applications. In this work we address both of these challenges with a spherical neural light field model for implicit panoramic image stitching and re-rendering; able to accommodate for depth parallax, view-dependent lighting, and local scene motion and color changes during capture.
Fit during test-time to a panoramic video capture, these neural light spheres jointly estimate the camera path and a high-resolution scene reconstruction to produce novel wide field-of-view projections of the environment. Our single-layer model avoids expensive volumetric sampling, and decomposes the scene into compact view-dependent ray offset and color components, with a total model size of 80 MB per scene, and real-time (50 FPS) rendering at 1080p resolution.
(In additional to this model, we also release our open-source Android RAW data collection app, and dataset of 50 metadata-rich scenes we captured with it for this project.)
Neural Light Spheres for Implicit Image Stitching and View Synthesis
Ilya Chugunov, Amogh Joshi, Kiran Murthy, Francois Bleibel, Felix Heide
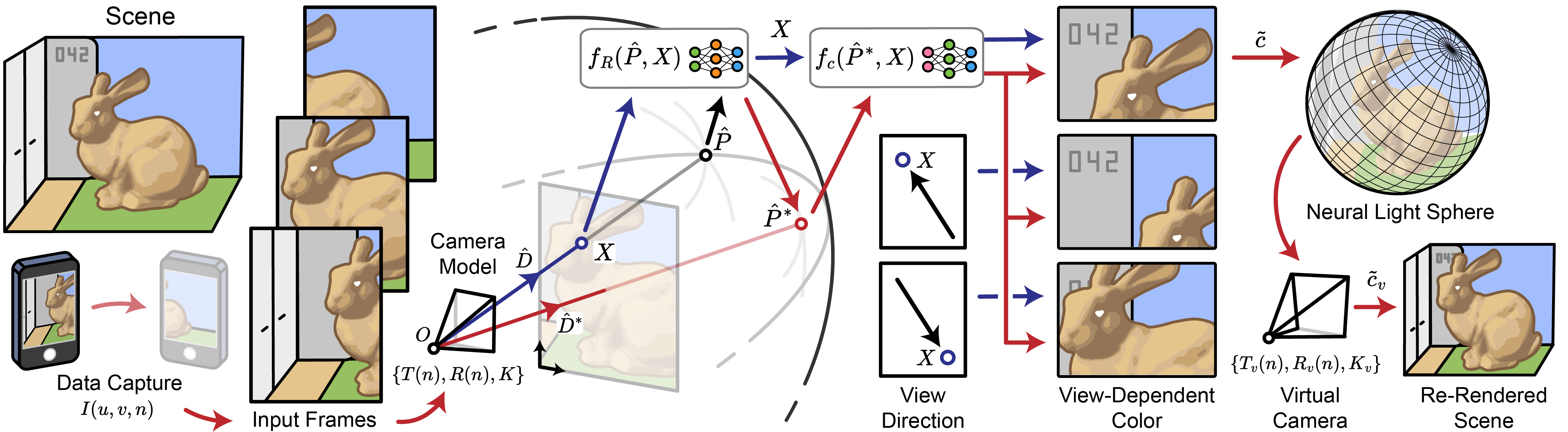
Neural Light Sphere Model
We represent the scene as a learned ray projection model combined with a 3D camera motion model. We calculate the intersections of rays cast from the camera model with a spherical hull, and pass these into a neural field ray offset model, which bends the rays to account for parallax and scene motion. The corrected intersections are then passed into a view-dependent color model, also backed by a neural field, which captures effects such as reflections, occlusions, and dynamic color changes in the scene.
Two Stage Training
Instead of using a separate pre-processing step like COLMAP to estimate camera poses, we initialize poses with the phone’s on-board gyroscope data and jointly optimize them with the neural light sphere model. We divide training into two stages: in the first stage, we freeze the view-dependent ray offset and color components while introducing random ray perturbations to slow convergence, allowing the model to estimate rough camera poses. In the second stage, we unlock all components and train them together to refine the final model. As illustrated in the example on the right, this two-stage process is crucial for training stability and high-quality scene reconstruction.
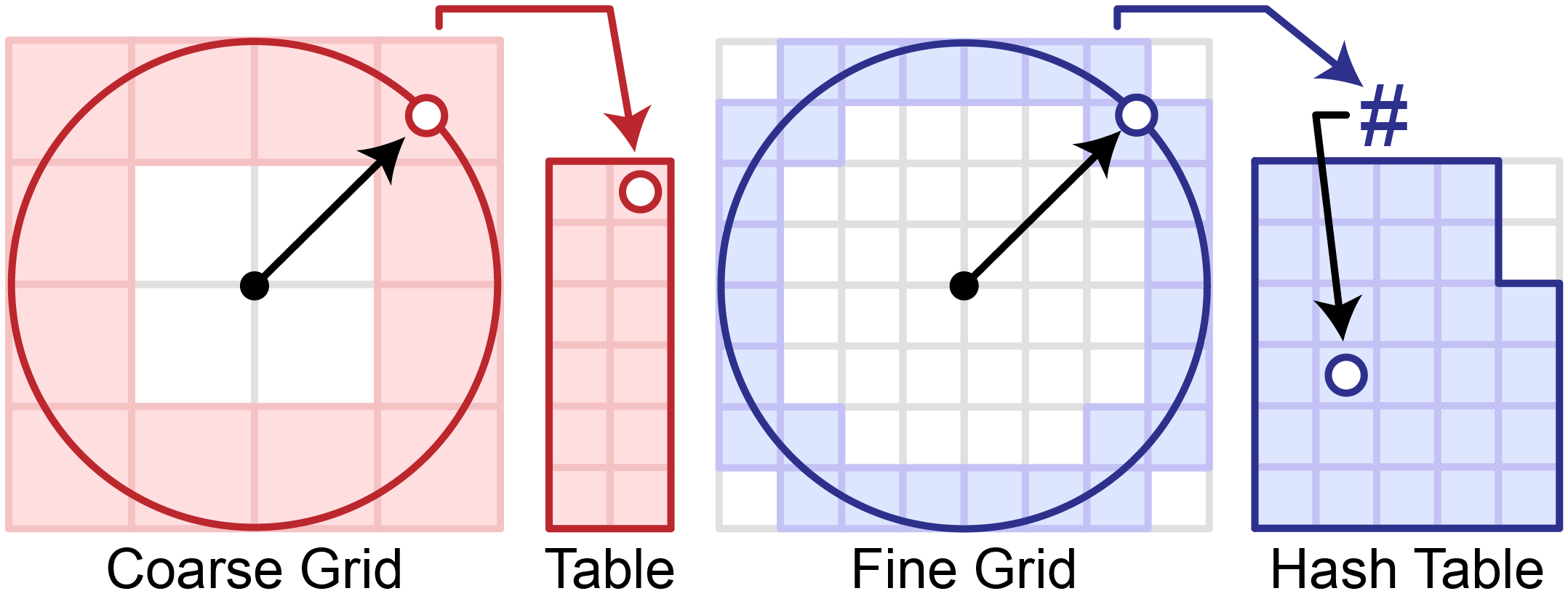
Hash Sphere Encoding
Diverging from traditional panorama reconstruction pipelines, our neural light sphere approach never converts intersections to spherical coordinates. Instead, values on the sphere’s surface are stored directly in 3D, utilizing an efficient multi-resolution hash grid, avoiding the non-linear projection and singularity issues that typically arise when mapping a spherical surface to 2D coordinates.
Scene Reconstruction
With no user input required beyond selecting a folder to load data, our method automatically transforms a panoramic capture into an interactive wide-view reconstruction, capturing effects such as parallax, reflections, and dynamic scene content. By avoiding costly volume sampling and instead generating ray colors through explicit ray-sphere crossings, our lightweight neural light sphere model can render these 1080p outputs in real time.
Night Photography
Fit directly to linear RAW image data, our model proves resilient to high sensor read noise, enabling nighttime scene reconstruction from image sequences captured at ISO 10,000.
Not a Pan? Not a Problem
As our neural light sphere makes no motion assumptions (e.g, purely rotational/cylindrical motion), and jointly estimates 3D camera poses, we can reconstruct scenes with arbitrary camera trajectories. Shown above are example captures with 360 degree, back-and-forth, up-and-down, and random walk camera paths.
Beyond the Main Lens
Our panorama dataset includes not only main lens (1x), but also telephoto (5x) and ultrawide (0.5x) captures recorded with our custom Android capture app. As our model ingests the recorded lens distortion and camera intrinsics metadata, these other magnification settings require no manual parameter adjustments to reconstruct.
Related Publications
[1] Ilya Chugunov, David Shustin, Ruyu Yan, Chenyang Lei, and Felix Heide. Neural Spline Fields for Burst Image Fusion and Layer Separation. CVPR 2023
[2] Ilya Chugunov, Yuxuan Zhang, and Felix Heide. Shakes on a Plane: Unsupervised Depth Estimation from Unstabilized Photography. CVPR 2023
[3] Ilya Chugunov, Yuxuan Zhang, Zhihao Xia, Cecilia Zhang, Jiawen Chen, and Felix Heide. The Implicit Values of a Good Hand Shake: Handheld Multi-Frame Neural Depth Refinement. CVPR 2022