
ScatterNeRF: Seeing Through Fog with Physically-Based
Inverse Neural Rendering
- Andrea Ramazzina
- Mario Bijelic
- Stefanie Walz
- Alessandro Sanvito
-
Dominik Scheuble
- Felix Heide
ICCV 2023
The top row shows a foggy scene (left), a neural reconstruction of that foggy scene using ScatterNeRF (center) that models scattering in the scene, and the decomposed background "defogged" component learned by ScatterNeRF (right). In the bottom row, dehazing results from different state-of-the-art dehazing methods (ZeroRestore[4], PFF[5], EPDN[6]) are shown. ScatterNeRF is able to learn a realistic and temporally-consistent defogged scene, solely by fitting image observations from the original scene.
Vision in adverse weather conditions, whether it be snow, rain, or fog is challenging. In these scenarios, scattering and attenuation severly degrades image quality. Handling such inclement weather conditions, however, is essential to operate autonomous vehicles, drones and robotic applications where human performance is impeded the most. A large body of work explores removing weather-induced image degradations with dehazing methods. Most methods rely on single images as input and struggle to generalize from synthetic fully-supervised training approaches or to generate high fidelity results from unpaired real-world datasets. We introduce ScatterNeRF, a neural rendering method which adequately renders foggy scenes and decomposes the fog-free background from the participating media, as exemplified in the video above, exploiting the multiple views from a short automotive sequence without the need for a large training data corpus. Instead, the rendering approach is optimized on the multi-view scene itself, which can be typically captured by an autonomous vehicle, robot or drone during operation. Specifically, we propose a disentangled representation for the scattering volume and the scene objects, and learn the scene reconstruction with physics-inspired losses.
Paper
ScatterNeRF: Seeing Through Fog with Physically-Based Inverse Neural Rendering
Andrea Ramazzina, Mario Bijelic, Stefanie Walz, Alessandro Sanvito, Dominik Scheuble, Felix Heide
ICCV 2023
Disentangled Scene Representation
In this work, we depart from both feed-forward dehazing methods and fully synthetic training data, and we address this challenge as an inverse rendering problem. Instead of predicting clean images from RGB frames, we propose to learn a neural scene representation that explains foggy images with a physically accurate forward rendering process. Specifically, we propose a disentangled representation for the scattering volume and the scene objects, and we learn the scene reconstruction with physics-inspired losses. The total image formation model for the original hazed scene is therfore defined as:
$$\mathbf{C}_F(\mathbf{r}) =\ \int_{t_n}^{t_f} T_c(t) \underbrace{\left(T_p(t) \sigma_p(\mathbf{r}(t)) \mathbf{c}_p(\mathbf{r}(t)) \right)}_{\text{Fog Contribution}} \nonumber \quad + T_p(t)\underbrace{\left(T_c(t)\sigma_c(\mathbf{r}(t)) \mathbf{c}_c(\mathbf{r}(t)) \right) }_{\text{Clear scene contribution}}dt.$$
Once this representation is fitted to a scene, this allows us to render novel views with real-world physics-based scattering, disentangle appearance and geometry without scattering (i.e., reconstruct the dehazed scene), and estimate physical scattering parameters accurately, as shown in the figure below.
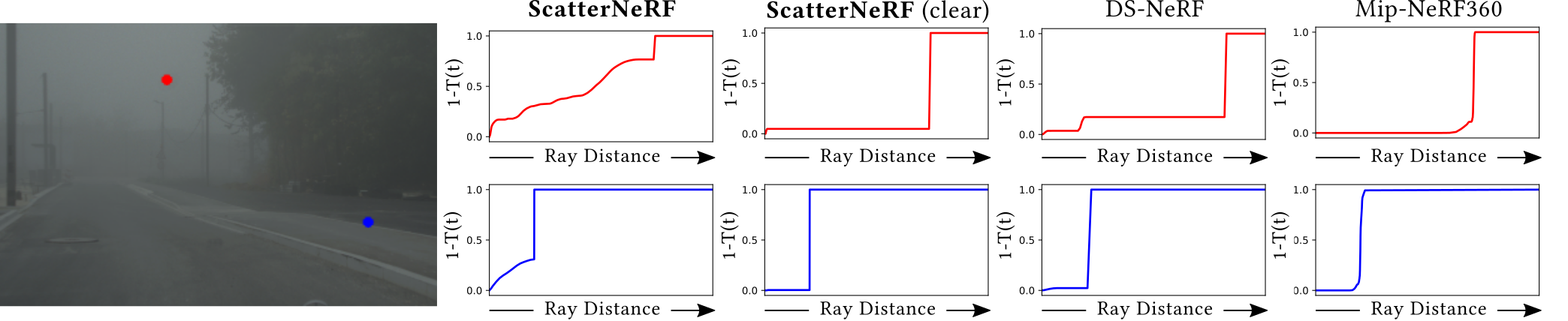
We show the ray termination distribution along two cast rays for our approach and two references NeRF models. The regularization methods proposed in DS-NeRF and mip-NeRF-360 find the accumulated transmittance $T$ as a step function, whereas ScatterNeRF models the scattering present in the original scene, while also representing the correct geometry for the cleared scene.
Fog-Unbiased SamplingInstead of sampling across the whole volume density we adapt the approach to our decomposed volume densities $\sigma_c$ and $\sigma_F$. As $\sigma_F$ is regularized to be approximately constant across the scene, the re-sampling procedure is not going to be performed using the scene weights $w_F = T_F (1-\exp(\sigma_F \delta))$ but rather using the clear scene $w_c = T_c (1-\exp(\sigma_c \delta) )$. We apply this approach to follow an importance sampling and reconstruct scene objects by sampling close to object boundaries, as exemplified in the figure to the right. |
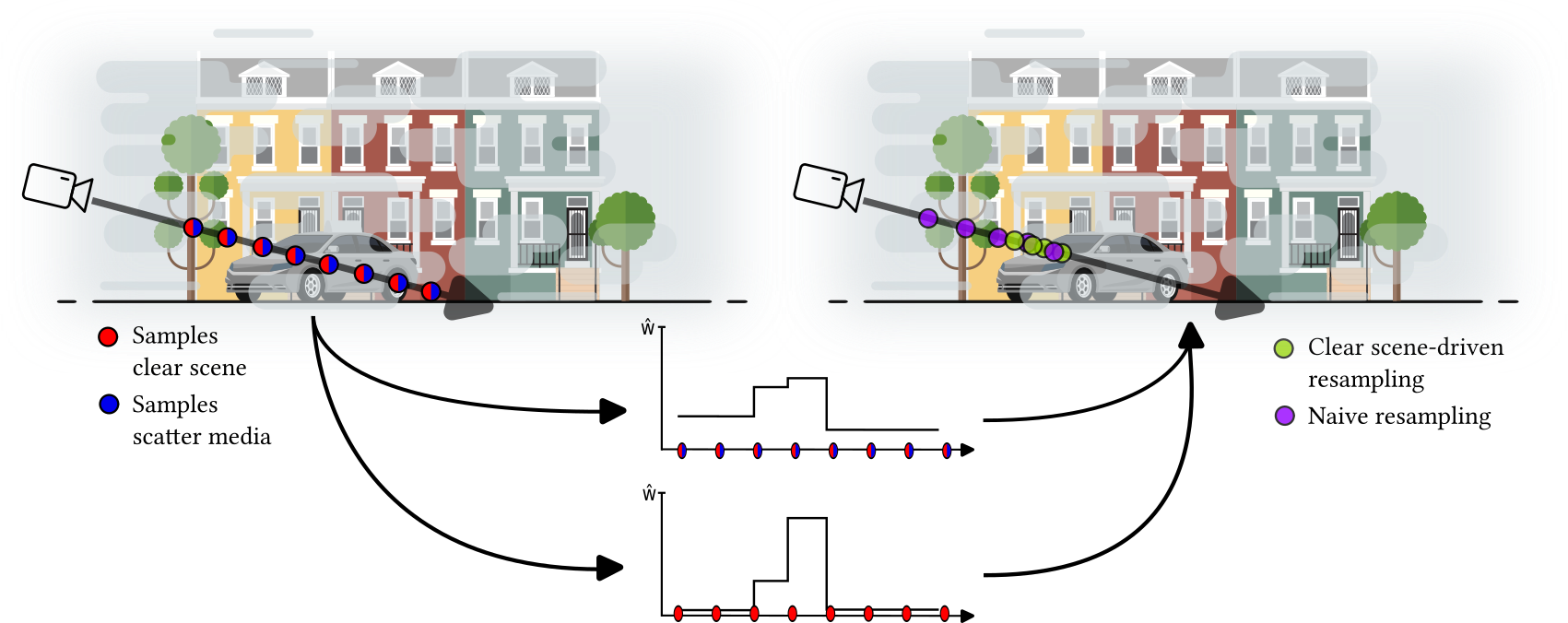
|
In-the-Wild Experiments
Qualitative comparison of dehazed images on real-world automotive measurements. The proposed ScatterNeRF enables enhanced contrast and visibility compared to state-of-the-art descattering methods
Fog Chamber ExperimentsIn order to validate our model performances in image descattering, we also collected a dataset of scenes in a large-scale fog chamber with two different fog densities as well as the cleared ground truth, shown in the images below. This allows us to validate our proposed model on real world scenes and with available ground truth data. |

Fog EditingWith our rendering pipeline, we cannot only remove the fog, as shown in the video and figure above for In-the-Wild and Fog Chamber settings, but also alter its density arbitrarily. Changing the fog density can be achieved by scaling the predicted scattering volume density $\sigma_p$ by a factor $\alpha$. Therefore, the new fog density $\sigma_p’$ can be computed as $\sigma_p’ = \alpha \sigma_p$ with $\alpha \in \mathbb{R}^+$ . |
ScatterNeRF Dataset
To evaluate the proposed method, we collect both an automotive In-the-Wild foggy dataset and a controlled fog dataset.
In-the-Wild Dataset
In total, we collect 2678 In-the-Wild foggy images throughout nine different scenarios.The sensor set for the In-the-Wild dataset consists of an Aptina-0230 stereo camera pair and a Velodyne HDL64S3D laser scanner. Camera poses are estimated with the hierarchical localization approach, a structure from motion pipeline optimized for robustness to changing conditions. The training and testing split was done by randomly choosing 30% of the images as test set.Each scene contains between 150 and 300 images.

Controlled-Environment Dataset
The controlled fog dataset is captured in a fog chamber where fog with varying visibilities can be generated. We capture 903 images in a large-scale fog chamber with clear ground-truth and two different fog densities. Further ground-truth depths are captured through a Leica ScanStation P30 laser scanner. Each point cloud consists of approximately 157M points and we accumulate multiple point clouds from different positions to reduce occlusions and increase resolution.

Related Publications
[1] Zheng Shi, Ethan Tseng, Mario Bijelic, Werner Ritter and Felix Heide. ZeroScatter: Domain Transfer for Long Distance Imaging and Vision through Scattering Media The IEEE International Conference on Computer Vision (CVPR), 2021.
[2] Kangle Deng, Andrew Liu, Jun-Yan Zhu and Deva Ramanan. Depth-supervised NeRF: Fewer Views and Faster Training for Free The IEEE International Conference on Computer Vision (CVPR), 2022.
[3] Stefanie Walz, Mario Bijelic, Andrea Ramazzina, Amanpreet Walia, Fahim Mannan and Felix Heide. Gated Stereo: Joint Depth Estimation from Gated and Wide-Baseline Active Stereo Cues The IEEE International Conference on Computer Vision (CVPR), 2023.
[4] Bai Haoran, Pan Jinshan, Xiang Xinguang and Tang Jinhui. Self-Guided Image Dehazing Using Progressive Feature Fusion IEEE Transactions on Image Processing 2022
[5] Yanyun Qu, Yizi Chen, Jingying Huang and Yuan Xie. Enhanced Pix2pix Dehazing Network The IEEE International Conference on Computer Vision (CVPR), 2019.