
SAMFusion: Sensor-Adaptive Multimodal Fusion for 3D Object Detection in Adverse Weather
- Edoardo Palladin
-
Roland Dietze
- Praveen Narayanan
- Mario Bijelic
- Felix Heide
ECCV 2024
Multimodal sensor fusion is an essential capability for autonomous robots, enabling object detection and decision-making in the presence of failing or uncertain inputs. While recent fusion methods excel in normal environmental conditions, these approaches fail in adverse weather, e.g., heavy fog, snow, or obstructions due to soiling. We introduce a novel multi-sensor fusion approach tailored to adverse weather conditions. In addition to fusing RGB and LiDAR sensors, which are employed in recent autonomous driving literature, our sensor fusion stack is also capable of learning from NIR gated camera and radar modalities to tackle low light and inclement weather. We fuse multimodal sensor data through attentive, depth-based blending schemes, with learned refinement on the Bird’s Eye View (BEV) plane to combine image and range features effectively. Our detections are predicted by a transformer decoder that weighs modalities based on distance and visibility. We demonstrate that our method improves the reliability of multimodal sensor fusion in autonomous vehicles under challenging weather conditions, bridging the gap between ideal conditions and real-world edge cases. Our approach improves average precision by 17.2 AP compared to the next best method for vulnerable pedestrians in long distances and challenging foggy scenes.
Below, we showcase SAMFusion’s performance in 3D object detection at day and night time on a proprietary long-range dataset (up to 250m). The perspective and bird’s-eye views demonstrate the strength of the novel depth-based encoder and the learned distance-weighting multimodal decoder proposals module.
Perspective and BEV visualization of long range SAMFusion detections in day and night time.
Paper
SAMFusion: Sensor-Adaptive Multimodal Fusion for 3D Object Detection in Adverse Weather
Edoardo Palladin, Roland Dietze, Praveen Narayanan, Mario Bijelic , Felix Heide
ECCV 2024
SAMFusion
SAMFusion leverages the complementary strengths of LiDAR, radar, RGB, and gated cameras. Gated cameras excel in foggy and low-light conditions, while radar is effective in rain and at long distances. By integrating these sensors into a depth-based feature transformation, a multi-modal query proposal network and a decoder head, SAMFusion ensures robust and reliable 3D object detection across diverse scenarios.
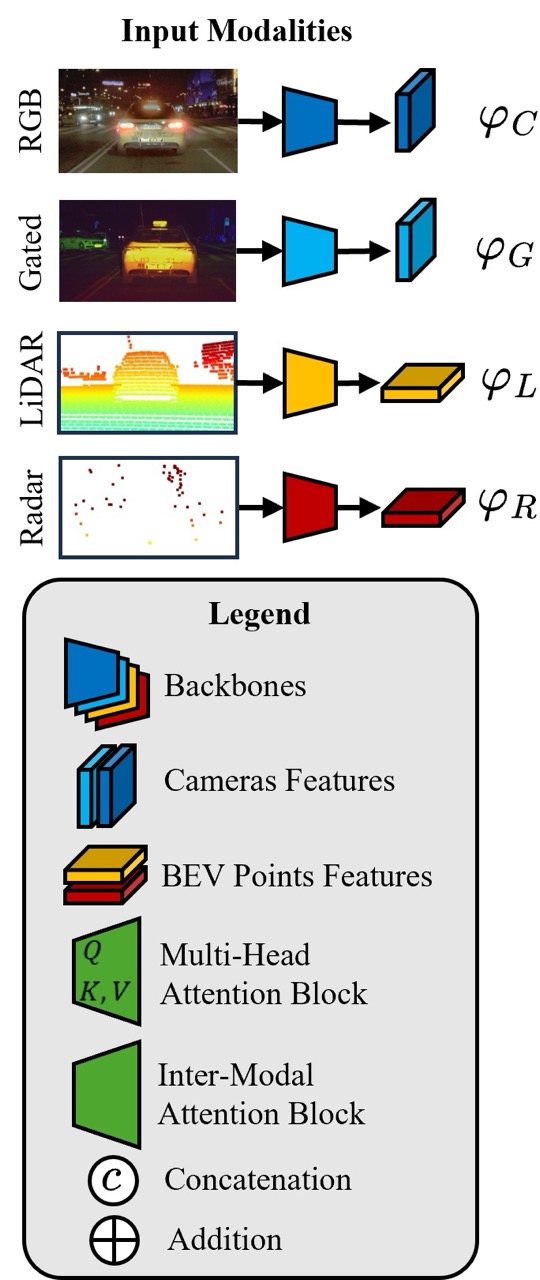
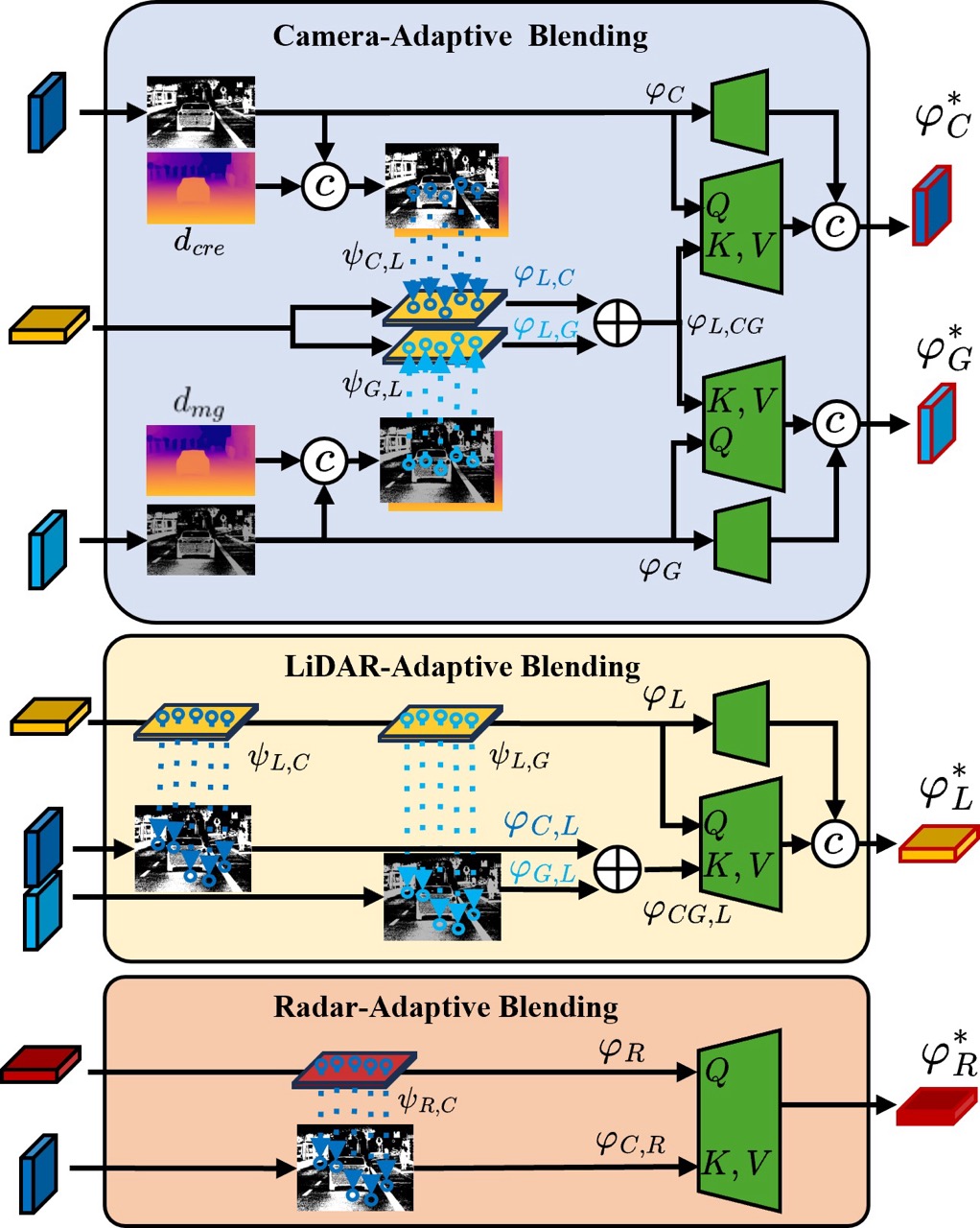
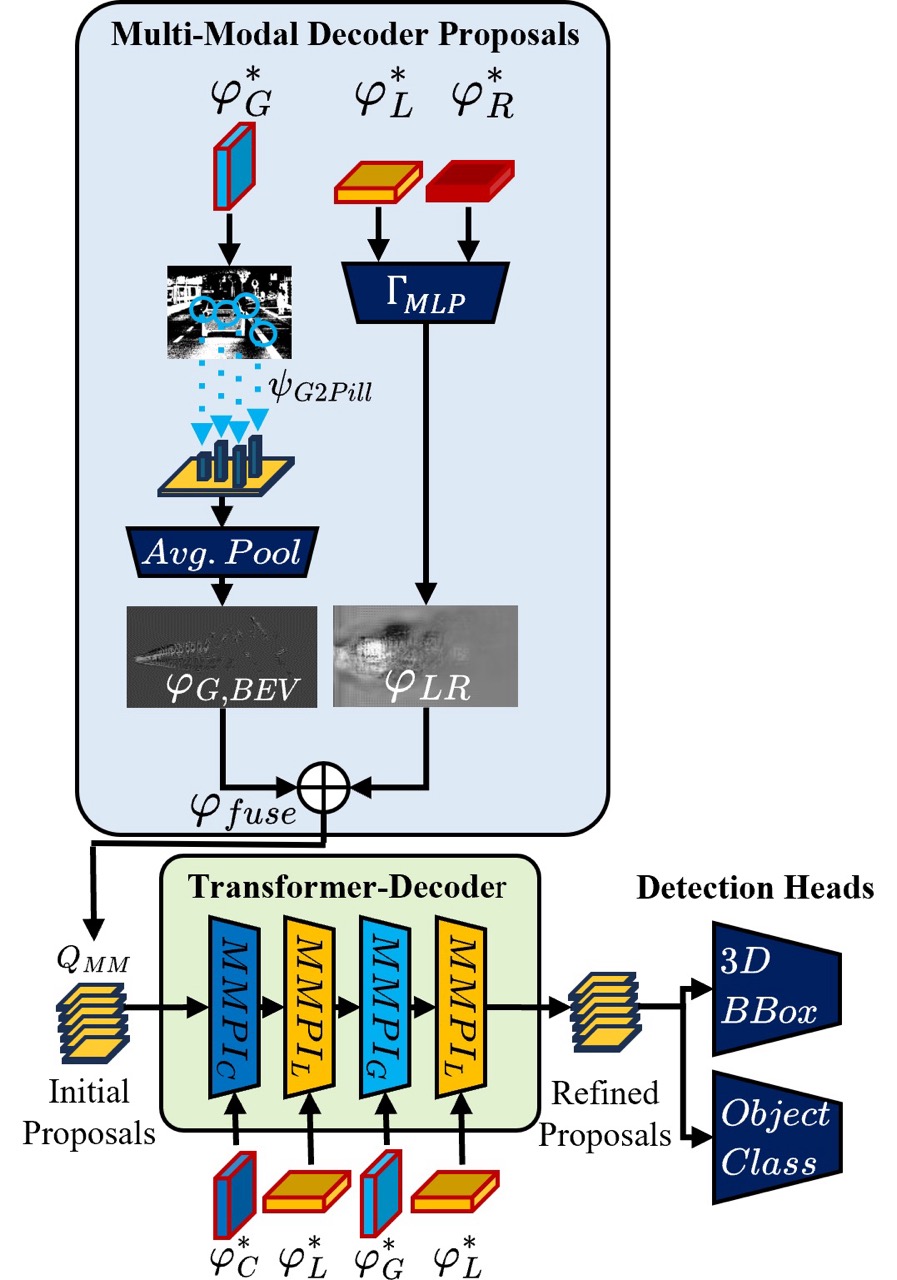
The inputs – RGB/gated camera, LiDAR, radar – are transformed into features through their respective feature extractors. These features are blended in the Multi-Modal encoder in an attentive fashion, and are combined with camera-specific feature maps to produce enriched features φ∗ – we refer to this as “early fusion”. Features φ∗ are now passed to the multi-modal decoder proposal module where they are refined with another level of fusion in the Bird’s Eye View representation to combine the image features (gated camera) and the range features (LiDAR, radar) in an adaptive, distance-weighted fashion for initial object proposals. Additionally, the enriched features φ∗ are sent to the transformer decoder that refines the initial object proposals to attentively produce detection outputs. The decoder proposals include optimizations to adaptively weight distance through a learned weighting scheme that is aware of the physical properties of ranging sensors while fusing with the information-dense camera modality.
Results on Adverse Weather
State of the art LiDAR-RGB methods struggle with reduced visibility and back-scatter in adverse weather, causing such fusion approaches to perform significantly worse than in clear conditions, despite the relatively simple scene configurations.
We evaluate our proposed model and multiple SOTA methods on the SeeingThroughFog dataset.
Relative to these baselines, SAMFusion achieves improvements of up to 13.6 AP (20.4% relative) for pedestrians at mid- range and 15.62 AP (60.51% relative) at long-range compared to the second-best (LiDAR and RGB) method in snowy scenes. In foggy scenes SAMFusion achieves high margins of up to 17.2 AP (101.2% relative) for pedestrians. For the car class in foggy conditions, it achieves improvements of up to 4.6 AP (5.2% relative).
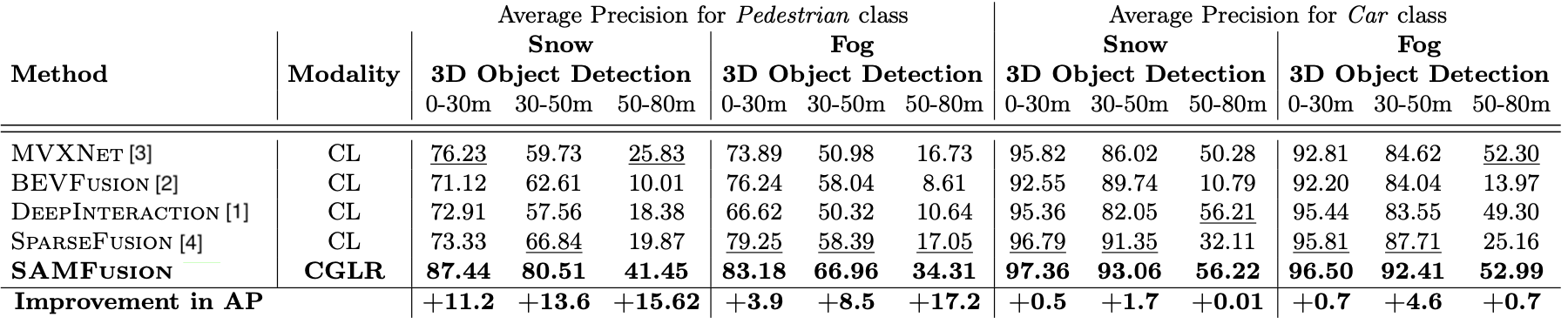
Detection performance of SAMFusion measured in AP compared to multi- modal methods in challenging weather conditions, evaluated on the car and pedestrian classes of weather test splits. We achieve margins of up to 17.2 AP against the second best model.
Qualitative Results
Qualitative results on 3D Object detection in adverse weather compared to state-of-the-art multi-modal sensor fusion methods and ground truth (GT).
While all methods perform well in the daytime setting, SAMFusion outperforms other reference methods in adverse and low light conditions (rain, snow, fog, twilight, night). In rainy and snowy settings, other methods show missing (BEVFusion) or spurious (MVXNet, DeepInteraction) detections, especially for the pedestrian class. In twilight and night, the effects are more pronounced, with missing and erroneous detections in most objects. Moreover, we see SAMFusion excel with far-away objects and pedestrian detection.

We show qualitative results on different sequences (rows) of the proposed method and reference approaches (columns). On the left the ground truth is illustrated with red bounding boxes, followed by the proposed SAMFusion approach, BEVFusion, MVX-Net and DeepInteraction.
Additional Qualitative Results with Relative BEV detections
We show additional comparisons to several existing methods for long and short ranges where the proposed approach excels.
We present additional qualitative results comparing the proposed model with SOTA methods, highlighting the detections in the BEV representation, see especially long ranges.
Related Publications
[1] Yang, Z., Chen, J., Miao, Z., Li, W., Zhu, X., Zhang, L. DeepInteraction: 3d object detection via modality interaction. Advances in Neural Information Processing Systems (NeurIPS), 2022.
[2] Liang, T., Xie, H., Yu, K., Xia, Z., Lin, Z., Wang, Y., Tang, T., Wang, B., Tang, Z. Bevfusion: A simple and robust lidar-camera fusion framework.. Advances in Neural Information Processing Systems (NeurIPS), 2022.
[3] Sindagi, V.A., Zhou, Y., Tuzel, O. Mvx-net: Multimodal voxelnet for 3d object detection.. International Conference on Robotics and Automation (ICRA), 2019.
[4] Xie, Y., Xu, C., Rakotosaona, M.J., Rim, P., Tombari, F., Keutzer, K., Tomizuka, M., Zhan, W. Sparsefusion: Fusing multi-modal sparse representations for multi- sensor 3d object detection.. International Conference on Computer Vision (ICCV), 2023.