
In the Blink of an Eye: Event-based Emotion Recognition
-
Haiwei Zhang
-
Jiqing Zhang
- Bo Dong
- Pieter Peers
-
Wenwei Wu
-
Xiaopeng Wei
- Felix Heide
- Xin Yang
SIGGRAPH 2023
We propoose a wearable single-eye emotion recognition prototype system comprised of a bio-inspired event-based camera (DAVIS346) and a low-power NVIDIA Jetson TX2 computing device. Event-based cameras simultaneously provide intensity and corresponding events, which we input to a newly designed lightweight Spiking Eye Emotion Network (SEEN) to extract and combine spatial and temporal cues for emotion recognition. Given an event video, SEEN takes the start and end intensity frames (green boxes) along with $n$ intermediate event frames (red boxes) as input. Our prototype system consistently recognizes emotions based on single-eye areas under different lighting conditions at $30$ FPS.
Paper
Haiwei Zhang, Jiqing Zhang, Bo Dong, Pieter Peers, Wenwei Wu, Xiaopeng Wei, Felix Heide, Xin Yang
In the Blink of an Eye: Event-based Emotion Recognition
SIGGRAPH 2023
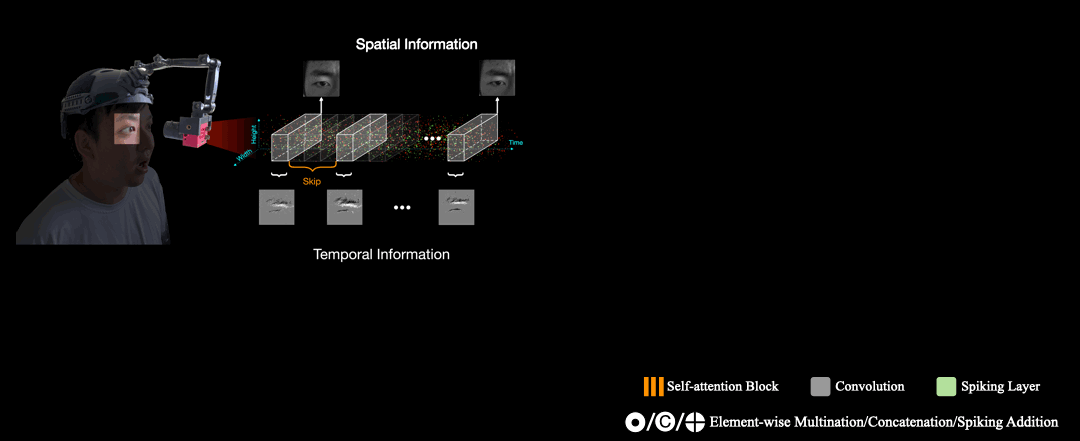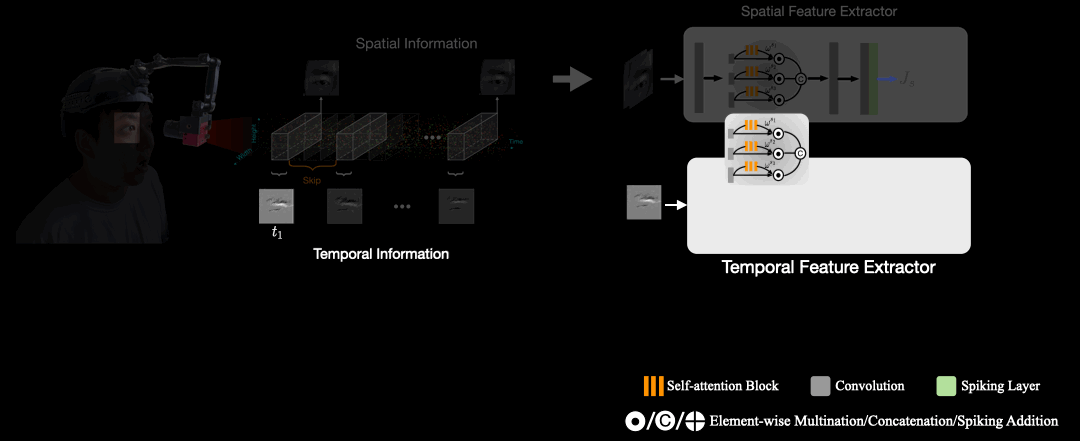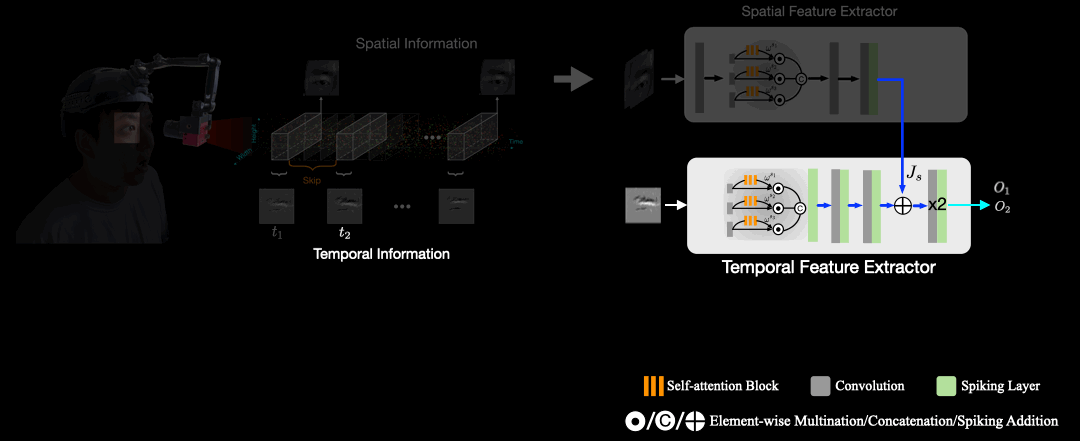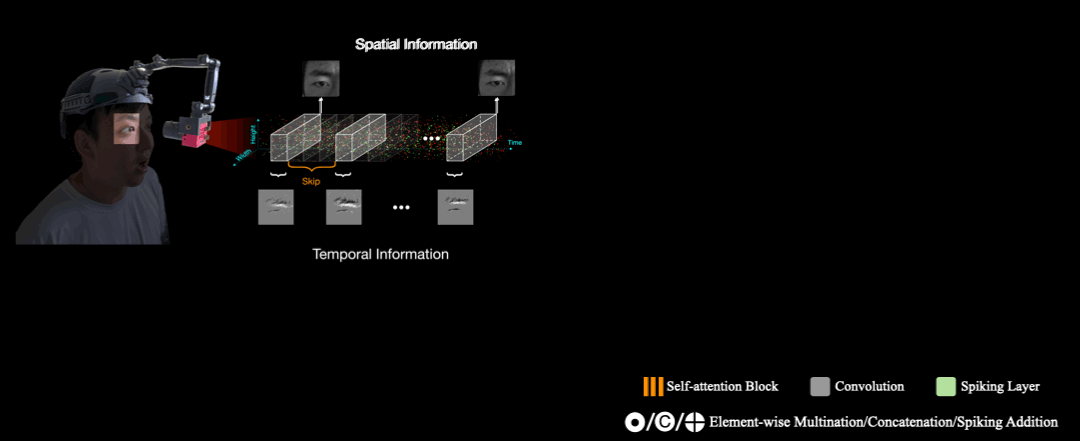
Spiking Eye Emotion Network (SEEN)
The architecture of SEEN consists of spatial feature extractor and a temporal feature extractor. Give two intensity frames, SEEN interpolates the asynchronous captured events between both intensity frames in $n$ synchronous event frames. Next, the spatial feature extractor distills spatial cues from the intensity frames, and the temporal feature extractor processes each of the $n$ event frames sequentially in time order. Finally, the temporal features and the spatial cues are then combined to predict $n$ emotion scores. The final predicted emotion is based on the average of the $n$ scores. The core component of the temporal feature extractor is the SNN layers that make decisions based on membrane potentials to remember temporal information from previous event frames. As events lack sufficient texture information, which impedes the temporal feature extractor from considering spatial information. To alleviate this problem, we devise a weight-copy scheme that copies the weights from the spatial feature extractor to the temporal feature extractor.
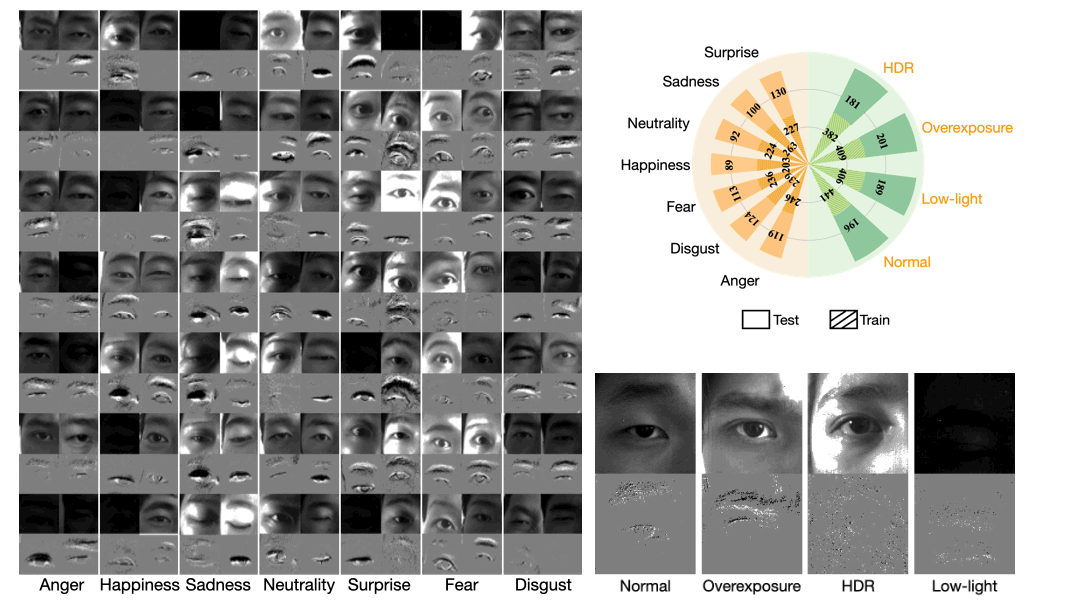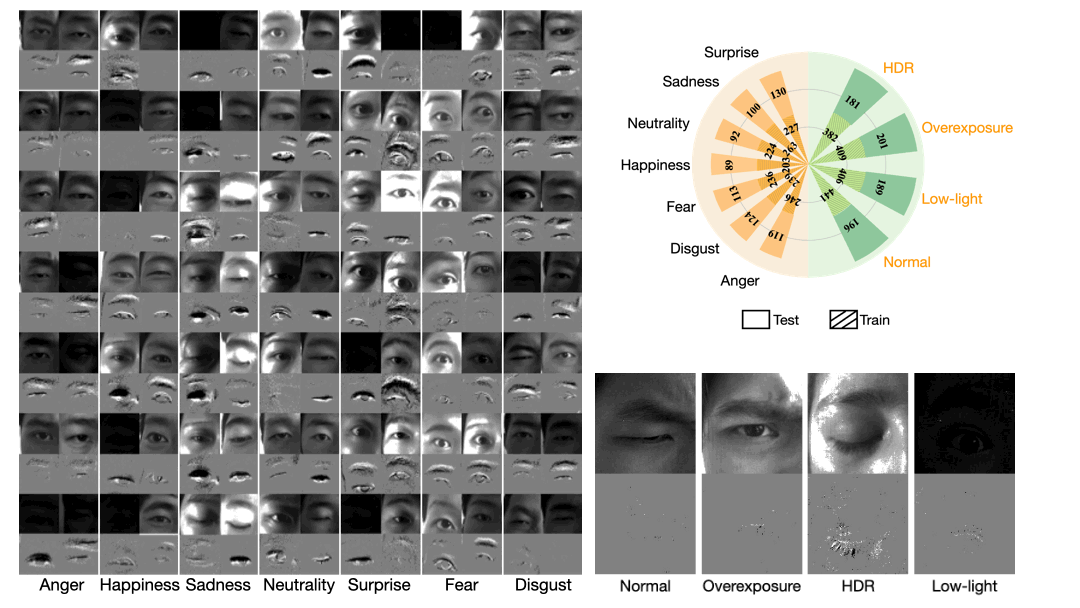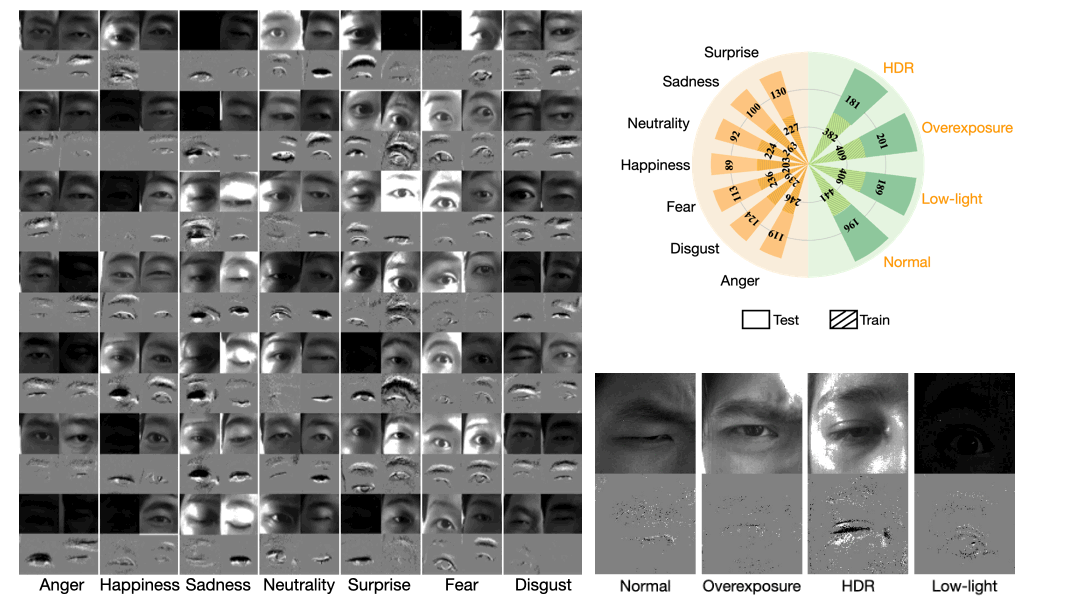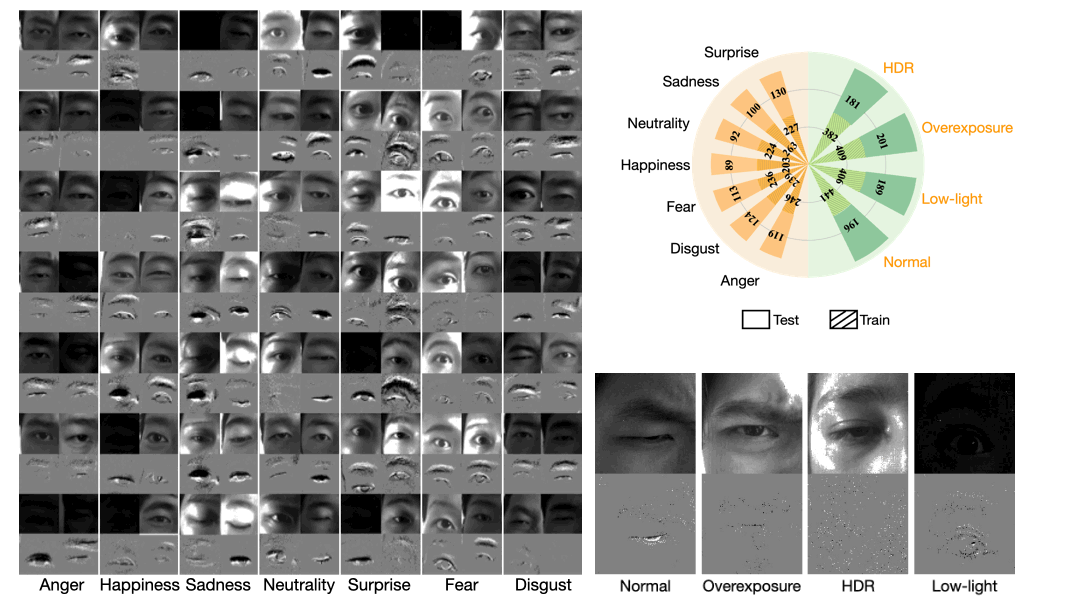
Single-eye Event-based Emotion (SEE) Dataset
We introduce a novel dataset, which we dub “SEE”, containing videos of 7 emotions under four different lighting conditions: normal, overexposure, low-light, and high dynamic range (HDR). The average video length ranges from 18 to 131 frames, with a mean frame number of 53.5 and a standard deviation of 15.2 frames, reflecting the differences in the duration of emotions between subjects. In total, SEE contains 2,405/128,712 sequences/frames with corresponding raw events for a total length of 71.5 minutes, which we split in 1,638 and 767 sequences for training and testing, respectively.
Experimental Findings under Different Lighting Conditions
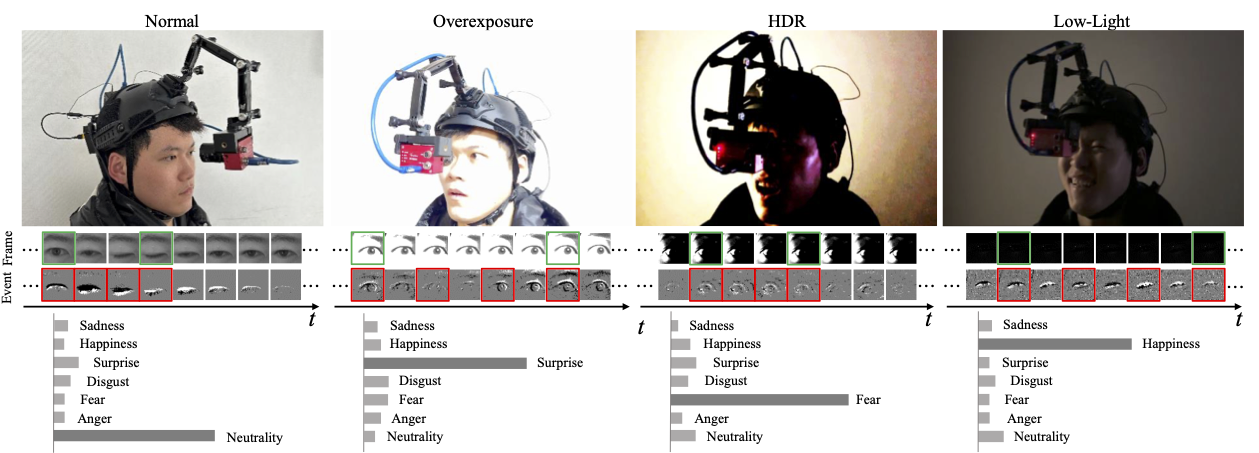
We show here four examples representing four different emotions: “Fear”, “Sadness”, “Surprise”, and “Happiness”, captured under four distinct lighting conditions. The frames highlighted with red boxes serve as inputs for both EMO and Eyemotion, and they are also the initial input frames for our approach. In the first example, we include the inputs for the experimental settings of E4-S0, E4-S1, and E4-S3. Notably, the method achieves the highest accuracy in emotion predictions across all test settings. Moreover, it is evident that our method performs even better with longer sequences, emphasizing the significance of temporal information in this task.
Related Publications
[1] Jianchuan Ding, Bo Dong, Felix Heide, Yufei Ding, Yunduo Zhou, Baocai Yin, Xin Yang Biologically Inspired Dynamic Thresholds for Spiking Neural Networks. NeurIPS, 2022
[2] Jiqing Zhang, Bo Dong, Haiwei Zhang, Jianchuan Ding, Felix Heide, Baocai Yin, and Xin Yang Spiking Transformers for Event-based Single Object Tracking. CVPR, 2022