
Neural Point Light Fields
 |
|
Neural Point Light Fields encode view-dependent radiance on a point cloud. View reconstructions can be learned from a single monocular RGB trajectory. Example view synthesis results from a front-facing monocular trajectory are shown above.
Neural Point Light Fields represent scenes with a light field living on a sparse point cloud. As neural volumetric rendering methods require dense sampling of the underlying functional scene representation, at hundreds of samples along each ray cast through the volume, they are fundamentally limited to small scenes with the same objects projected to hundreds of training views. Promoting sparse point clouds to neural implicit light fields allows us to represent large scenes effectively with only a single implicit sampling operation per ray.
These point light fields are a function of the ray direction, and local point feature neighborhood, allowing us to interpolate the light field conditioned training images without dense object coverage and parallax. We assess the proposed method for novel view synthesis on large driving scenarios, where we synthesize realistic unseen views that existing implicit approaches fail to represent. We validate that Neural Point Light Fields make it possible to predict videos along unseen trajectories previously only feasible to generate by explicitly modeling the scene.
Paper
Neural Point Light Fields
Julian Ost, Issam Laradji, Alejandro Newell, Yuval Bahat, Felix Heide
CVPR 2022
Point Light Fields
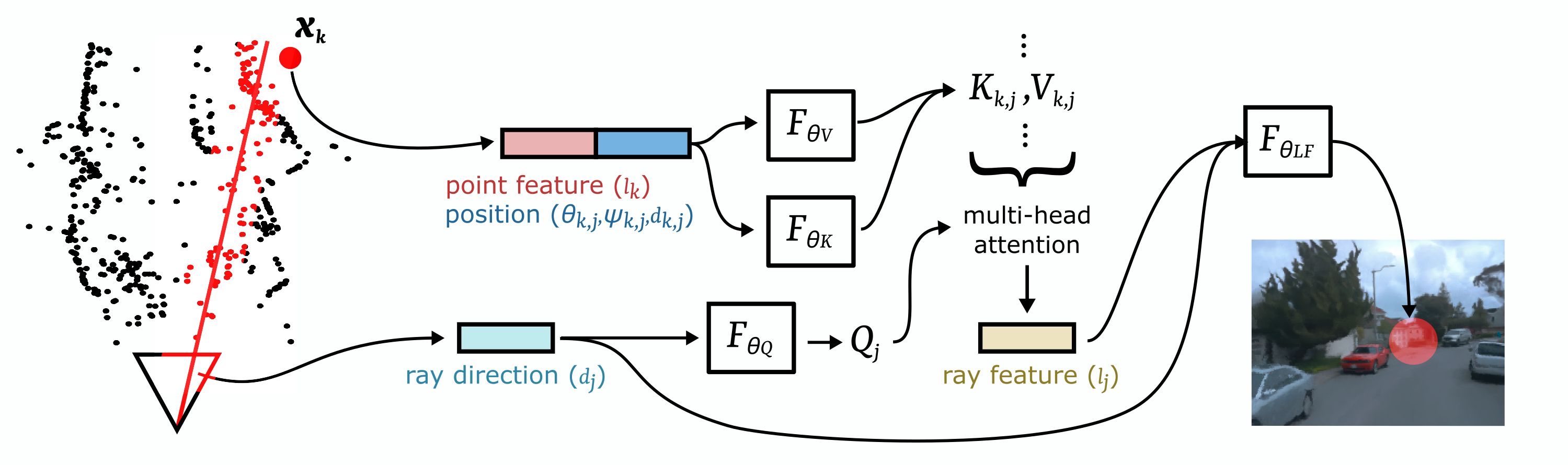
A Point Light Field encodes the light field of a scene on sparse point clouds. To learn a light field implicitly embedded on the point clouds corresponding to a video sequence, we devise three steps: an encoding step, a latent feature aggregation, and a point-conditioned light field prediction.
Point Features
We first produce a feature embedding for each point in the point cloud capture of the scene. The learned per-point features lk do not depend on any image data and can be trained end-to-end with the full light field rendering. We can introduce augmentations such that the model does not overfit to a particular arrangement of points. This includes sampling different subsets of points from the full captured point cloud, and using point cloud captures from nearby time steps.
![]()
Light Field Features
Given a set of points, and their encoded features, and a virtual camera, we aggregate the relevant features that reconstruct the local light field around each ray of this camera. For all pixels we cast a set of rays into the scene using a pinhole camera model. The local point cloud encoding can only explain the scene properties at their sparse locations. To explicitly represent high-frequency light field detail from all views a dense descriptor would be necessary. Instead, we implicitly interpolate a representation descriptor for each ray. Unlike volumetric or grid structured representations, we leverage the information given through the geometric properties of the point cloud. We aggregate a descriptor lj for each ray from a relevant set of sparse points.
Experimental Results
We quantitatively and qualitatively validate the proposed method on two tasks, reconstruction and novel view synthesis, where we compare against Generative Scene Networks (GSN), NeRF and depth-supervised NeRF (DS-NeRF).
Reconstruction
We present results for reconstructing images for poses seen during training. All methods were trained on the same set of scenes from the Waymo Open Dataset. NeRF (even with substantially increased model capacity) and DS-NeRF show similar blurriness and other artifacts, while the depth supervision allows DS-NeRF to improve over existing methods. GSN produces fewer artifacts while struggling to reconstruct fine details, and fails for sparsely observed views (center scene). Neural Point Light Fields most faithfully reconstruct the views along a given single-camera trajectory.
|
Reference |
Neural Point Light Fields |
DS-NeRF |
NeRF |
GSN |
Trajectory Extrapolation
We present a map of the novel view camera poses with respect to the training trajectory. While NeRF and DS-NeRF fail to synthesize views far from the training trajectory, our method is able to generate a set of novel trajectories and scenes, that can hardly be differentiated from the reconstruction results. This is possible within certain regions of the scene which are at least partially covered by the training images. Views of scene regions which were not seen during training, e.g., the back of a vehicle only seen from the front, resulting in imaginary objects, probably hallucinated from points similar to the observed objects. Extrapolating views are created between two points along the training trajectory and a shifted point left or right from the known trajectory.
|
Training Trajectory |
Neural Point Light Fields |
NeRF |
Related Publications
[1] Julian Ost, Fahim Mannan, Nils Thuerey, Julian Knodt and Felix Heide. Neural Scene Graphs for Dynamic Scenes. In IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2021