
Neural Scene Graphs for Dynamic Scenes
- Julian Ost
- Fahim Mannan
- Nils Thuerey
-
Julian Knodt
- Felix Heide
CVPR 2021 (Oral)
We present a first neural rendering approach that decomposes dynamic scenes into scene graphs. We propose a learned scene graph representation, which encodes object transformation and radiance, to efficiently render novel arrangements and views of the scene. To this end, we learn implicitly encoded scenes, combined with a jointly learned latent representation to describe objects with a single implicit function. We assess the proposed method on synthetic and real automotive data, validating that our approach learns dynamic scenes - only by observing a video of this scene - and allows for rendering novel photo-realistic views of novel scene compositions with unseen sets of objects at unseen poses.
Paper
Neural Scene Graphs for Dynamic Scenes
Julian Ost, Fahim Mannan, Nils Thuerey, Julian Knodt, Felix Heide
CVPR 2021 (Oral)
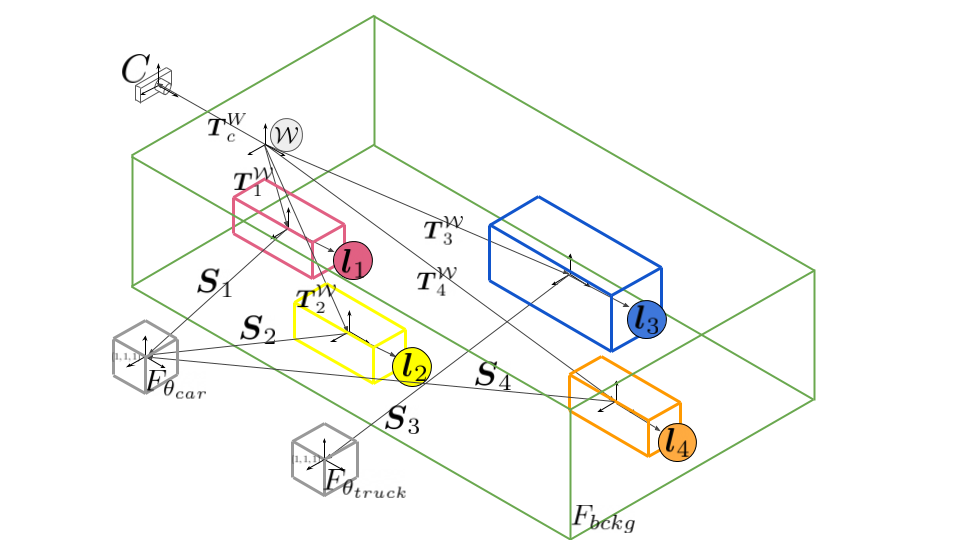
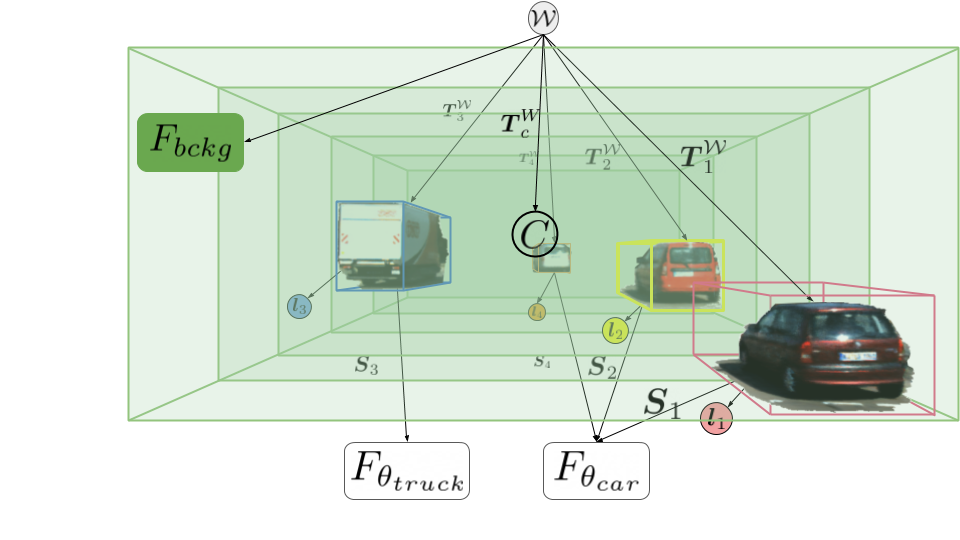
Neural Scene Graphs
We introduce the neural scene graph, which allows us to model scenes hierarchically. The scene graph S above is composed of a camera, a static node and and a set of dynamic nodes which represent the dynamic components of the scene, including the object appearance, shape, and class. We define a scene uniquely using a directed acyclic graph, where C is a leaf node representing the camera and its intrinsics K, the leaf nodes F represent both static and dynamic neural radiance fields [Mildenhall et al.], L are leaf nodes that assign latent object codes to each representation leaf node, and E are edges that either represent affine transformations T between the global world space and the local object or camera space or property assignments. A detailed description of all graph components and necessary adjustments to neural radiance fields is presented in our paper.

Rendering Pipeline
Our rendering approach leverages the above rendering pipeline, efficiently rendering images given a scene graph. In the section component of the pipeline, we demonstrate the two sampling approaches along a ray, inside the background (black) and an object (blue) node. To increase efficiency, we limit the sampling of the static node to multiple planes. For each ray, we predict color and density through each dynamic node through which it is traced, and we check each ray from the camera C for intersections with all dynamic nodes F by translating the ray to an object local frame and applying an efficient AABB-ray intersection test. The representation function F of a given node maps each point to a predicted color and density value. We use the rendering equation integrating over all sampling points along a ray from its origin to the global far plane to calculate the RGB values of the rendered image.
Reference Sequences
from KITTI / Virtual KITTI 2




Decomposed Background




Decomposed Objects




Reconstructed Scene




Scene Decomposition
Without additional supervision, the structure of the proposed scene graph model trained with the rendering pipeline naturally decomposes scenes into dynamic and static scene components and is able to reconstruct them individually and jointly.
Rotation

Translate
Scene Manipulation
A learned Neural Scene Graph can be manipulated at its edges and nodes. To demonstrate the flexibility of the proposed scene representation, we change the edge transformations of a learned node. Results validate that these transformations preserve global light transport components such as reflections and shadows. The scene representation encodes global illumination cues implicitly through image color, a function of an object's location and viewing direction. The specular highlights on the vehicles, especially on the red and silver car, move in accordance to the fixed scene illumination. This is in contrast to simply copying pixels, where we instead are learning to correctly translate specular highlights after moving the object.
Reconstruction of Dynamic Objects

Object Poses fixed at t=0.50

Object Poses fixed at t=0.25

Object Poses fixed at t=0.75

Camera Movement
Beyond object manipulation, and similar to prior methods, neural scene graphs allows for camera movement through adjustment of its transformation. The videos below show novel views for ego-vehicle motion into the scene, where the ego-vehicle is driving ~2 m forward. In contrast to static methods, we can actively manipulate the scene's arrangement by fixing all object's poses and by only moving the camera in contrast to a trained reference sequence.