
Self-Supervised Sparse Sensor Fusion for Long Range Perception
- Edoardo Palladin
- Samuel Brucker
-
Filippo Ghilotti
- Praveen Narayanan
- Mario Bijelic
- Felix Heide
ICCV 2025
Outside of urban hubs, autonomous cars and trucks have to master driving on intercity highways. Safe, long-distance highway travel at speeds exceeding 100 km/h demands perception distances of at least 250 m, which is about five times the 50–100m typically addressed in city driving, to allow sufficient planning and braking margins. Increasing the perception ranges also allows to extend autonomy from light two-ton passenger vehicles to large-scale forty-ton trucks, which need a longer planning horizon due to their high inertia. However, most existing perception approaches focus on shorter ranges and rely on Bird’s Eye View (BEV) representations, which incur quadratic increases in memory and compute costs as distance grows. To overcome this limitation, we built on top of a sparse representation and introduced an efficient 3D encoding of multi-modal and temporal features, along with a novel self-supervised pretraining scheme that enables large-scale learning from unlabeled camera-LiDAR data by predicting and forecasting the scene geometry (right). Our approach efficiently fuses camera (right) and lidar data, enables to extend perception distances to 250 meters and achieves an 26.6% improvement in mAP in object detection and a decrease of 30.5% in Chamfer Distance in LiDAR forecasting compared to existing methods, reaching distances up to 250 meters.
Self-Supervised Sparse Sensor Fusion for Long Range Perception
Edoardo Palladin*, Samuel Brucker*, Filippo Ghilotti, Praveen Narayanan, Mario Bijelic, Felix Heide
(* Equal Contribution)
ICCV 2025
Highway Scenarios vs Urban Scenarios
Mastering highway driving is essential for connecting urban centers and enabling scalable autonomous mobility. Unlike urban environments, highways demand perception over much greater distances to support high-speed navigation and long-term planning. As a result, the Region of Interest (ROI) in highway scenarios is significantly larger—28 times greater than that in typical urban settings. To reflect this, we introduce a novel Long Range Dataset tailored to highway driving, using an ROI of 350m × 200m, compared to the standard 50m × 50m in urban-focused datasets like nuScenes. The point cloud visualization below highlights the extended perception range required on highways. This contrast underscores the need for specialized perception systems that can handle the distinct operational challenges posed by highway environments versus urban ones.
Unlike urban environments, highway scenes are typically free from occlusions caused by buildings, trees, or complex infrastructure. This open layout allows for mostly unobstructed views that can extend up to 1000 meters, especially on straight road segments (illustrated below). As a result, relevant actors and scene context often appear at far distances, making it essential for perception systems to detect and reason about objects well beyond typical urban ranges. This inherent visibility in highway settings both enables and demands long-range sensing to ensure safe and anticipatory planning.
 |
LRS4Fusion
Long Range Self-Supervised Sparse Sensor (S4) Fusion (LRS4Fusion), addresses the unique challenges of highway driving by introducing a sensor fusion method specifically designed for long-range perception. It achieves improved performance over previous state-of-the-art approaches on both the nuScenes benchmark and our newly proposed long-range dataset. The method starts by lifting camera features into 3D using accurate depth maps, which are then fused with LiDAR features to form a unified sparse representation. This representation is further enhanced by fusing with temporal features through a sparse attention mechanism, before being processed by a Multi-Modal Late Encoder.
During the self-supervised pre-training phase, the encoded features are passed to both a sparse occupancy decoder and a velocity decoder. In contrast to existing state-of-the-art methods that pre-train uni-modal backbones using dense representations, our approach pre-trains the entire multimodal fusion pipeline—including both encoders and their integration—within a fully sparse framework. The model outputs predictions for future depth, occupancy, velocity, and LiDAR measurements, as well as object detection (OD) results.
3D Object Detection on the Long Range Dataset
Below, our method LRS4Fusion achieves state-of-the-art performance on the 3D Object Detection task. The accompanying video showcases qualitative results on challenging highway scenarios. The top row displays the input camera views, followed by the LiDAR point cloud in the middle row. The bottom row presents a multi-panel visualization with the nuScenes Detection Score (NDS) and corresponding map outputs for four methods—CenterPoint, BEVFusion, SAMFusion, and ours—with each method shown in a separate column. LRS4Fusion consistently detects vehicles at long ranges with higher accuracy and lower latency compared to prior approaches, clearly demonstrating its advantage in long-range, high-speed driving environments.
Long Range and Lost Cargo 3D Object Detection
Our method is able to detect vehicles as well as small lost cargo objects at long distances—beyond 200 m. The visualizations below include 3D bounding boxes for Car (cyan), Truck-Cab (blue), Truck-Trailer (orange), and Road Obstruction (yellow). Several still images are shown, with predicted and ground truth boxes displayed in the BEV LiDAR frame at the bottom for comparison. On the right, we highlight a particularly challenging case involving a small lost cargo object successfully detected by our method, demonstrating its robustness in long-range and safety-critical scenarios.


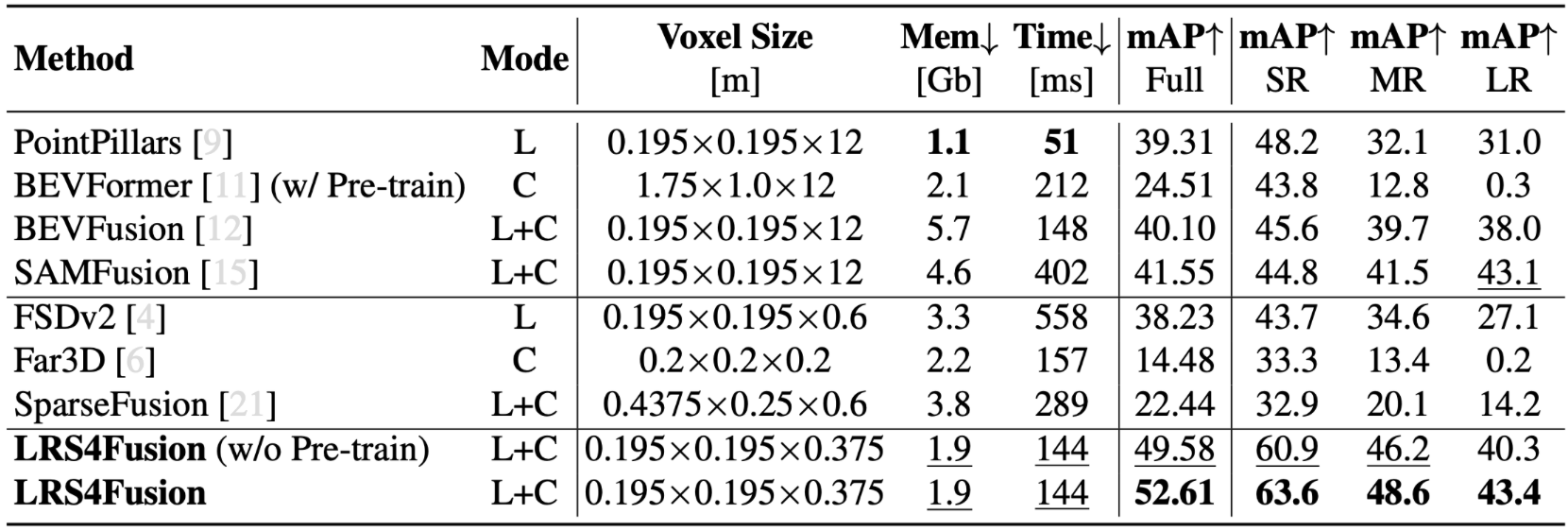
Quantitative Comparison with SOTA methods
Here we show the 3D Object Detection performance on the right (BEVFormer model pre-trained using ViDAR [65]). Our proposed method achieves state-of-the-art 3D mAP on the Long Range Dataset, while also demonstrating substantial improvements in memory efficiency and runtime—enabled by its fully sparse architecture and streamlined fusion strategy. Notably, incorporating occupancy-velocity self-supervision boosts mAP by +6.11% compared to the same model without self-supervision, underscoring the benefit of our approach for enhancing multimodal representation learning in long-range perception tasks.
Occupancy Prediction and LiDAR Reconstruction on the Long Range Dataset
Below, we present qualitative results for dense occupancy prediction and reconstructed LiDAR scans. From left to right, each example shows the input camera images, the predicted dense occupancy, the reconstructed LiDAR scan, and finally the ground truth LiDAR scan on the far right. LRS4Fusion accurately predicts dense occupancy in a fully self-supervised manner, using supervision derived directly from future LiDAR observations. Moreover, it reconstructs high-fidelity LiDAR scans even in challenging highway scenarios involving fast-moving objects and long-range scenes up to 250 meters.
The next example presents two additional scenes, illustrating the versatility of our method across different environments. On the left, we show the input camera images; on the right, the corresponding predicted dense occupancy maps. The first scene depicts a rural-urban intersection, while the second captures a highway scenario. These results further demonstrate LRS4Fusion’s ability to generalize across diverse settings and maintain accurate spatial understanding in both structured and high-speed environments.
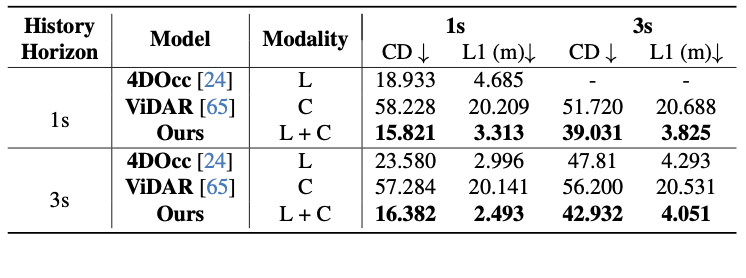
LiDAR Forecasting on the Long Range Dataset
On the right, we show qualitative visualizations of both occupancy and LiDAR forecasting. On the bottom, we provide quantitative comparisons of LiDAR forecasting performance on the Long Range Dataset. For these evaluations, we define the Region of Interest (ROI) relative to the ego vehicle as [+250 m, −100 m] along the X-axis (forward and backward) and [+100 m, −100 m] along the Y-axis (left and right), covering a wide area representative of highway driving conditions. These results further validate the model’s accuracy and robustness in predicting future scene geometry at long range.
LiDAR Forecasting on NuScenes
We present additional results on the Urban nuScenes benchmark, with qualitative visualizations on the left and quantitative comparisons on the right. Each row displays still images of predicted depth, occupancy, and LiDAR over an evolving 3-second time horizon, illustrating the model’s temporal forecasting capabilities.
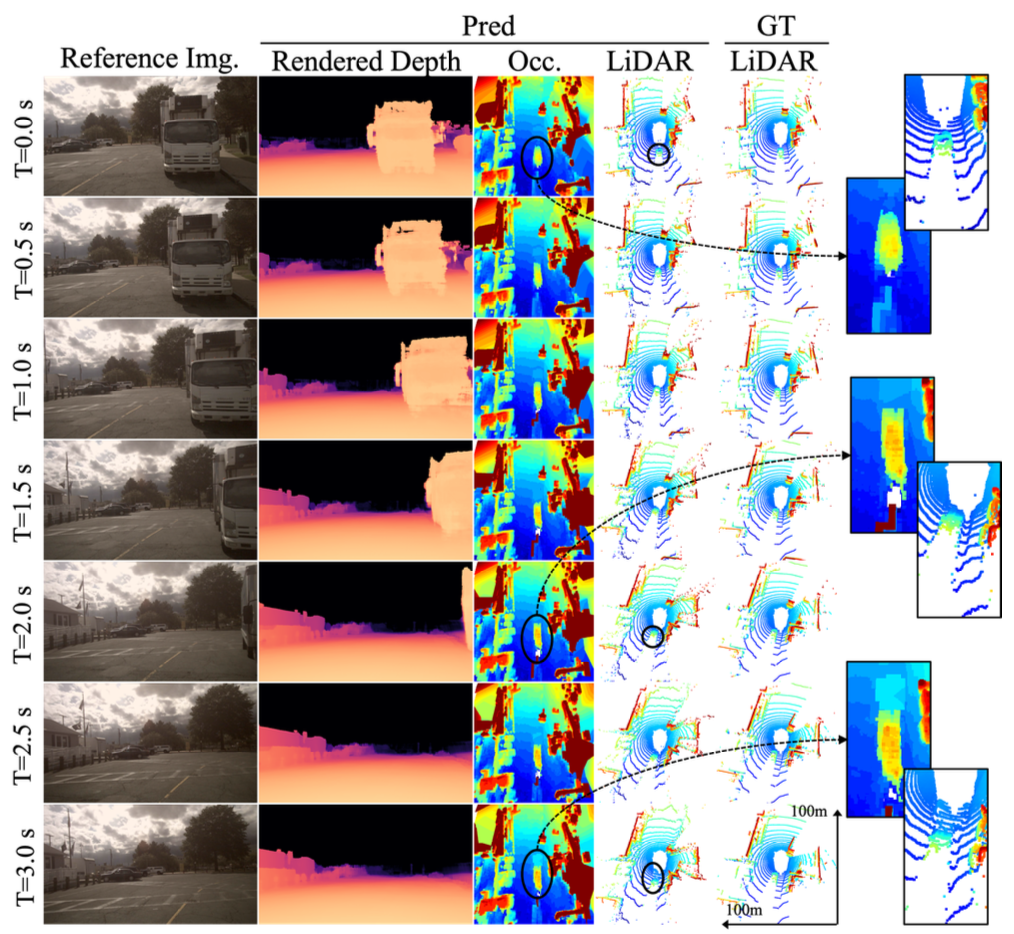
Our method produces future predictions up to 3 seconds on the Urban nuScenes Dataset, capturing fine spatial and temporal details. For instance, the occupancy decoder accurately reconstructs structural elements such as the upper components of a truck, while also forecasting the motion of surrounding agents, as seen in the predicted trajectory of a trailing car. Furthermore, the model effectively expresses uncertainty over time, visualized as a gradual spread of occupancy in ambiguous regions.
In the following table, we follow prior works and consider a Region of Interest (ROI) of 51.2 m on all sides around the ego vehicle. Results marked with † denote those reported in [65]:
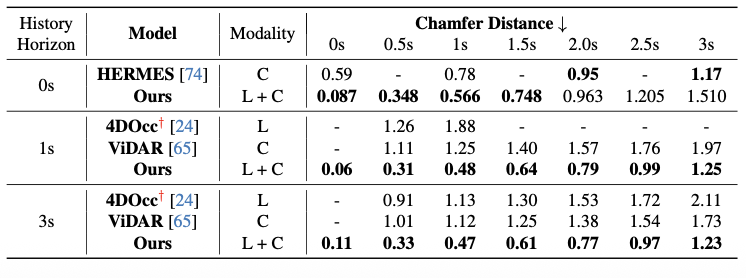
In the following table we follow UnO evaluation setting:

Related Publications
[1] Ben Agro, Quinlan Sykora, Sergio Casas, Thomas Gilles, Raquel Urtasun UnO: Unsupervised Occupancy Fields for Perception and Forecasting, CVPR, 2024.
[24] Tarasha Khurana, Peiyun Hu, David Held, Deva Ramanan Point Cloud Forecasting as a Proxy for 4D Occupancy Forecasting, CVPR, 2023.
[65] Zetong Yang, Li Chen, Yanan Sun, Hongyang Li Visual Point Cloud Forecasting enables Scalable Autonomous Driving, CVPR, 2024.