
Too Tiny to See: Hazardous Obstacle Detection Dataset and Evaluation
-
Topi Miekkala
- Samuel Brucker
- Stefanie Walz
- Filippo Ghilotti
- Andrea Ramazzina
- Dominik Scheuble
-
Pasi Pyykönen
- Mario Bijelic
- Felix Heide
3DV 2026
We present a benchmark for long-range depth estimation of small objects, enabling fair comparison between ToF sensors and learned depth methods. Accurate distant depth is crucial for autonomous driving, where small, slightly raised structures can signal hazardous obstacles, yet standard metrics overlook them by focusing on large planar regions. Our framework evaluates how well predicted point clouds preserve semantic and structural content using graph-based feature embeddings, offering modality-agnostic assessment of object-level fidelity and revealing trade-offs in resolution and robustness across sensors and learned models. On the right, we show examples across challenging conditions—night, snow, and long-range sensing—highlighting how different sensors vary in their ability to detect small obstacles.
Too Tiny to See: Hazardous Obstacle Detection Dataset and Evaluation
Topi Miekkala, Samuel Brucker, Stefanie Walz, Filippo Ghilotti, Andrea Ramazzina, Dominik Scheuble, Pasi Pyykönen, Mario Bijelic, Felix Heide
Lost Cargo Dataset
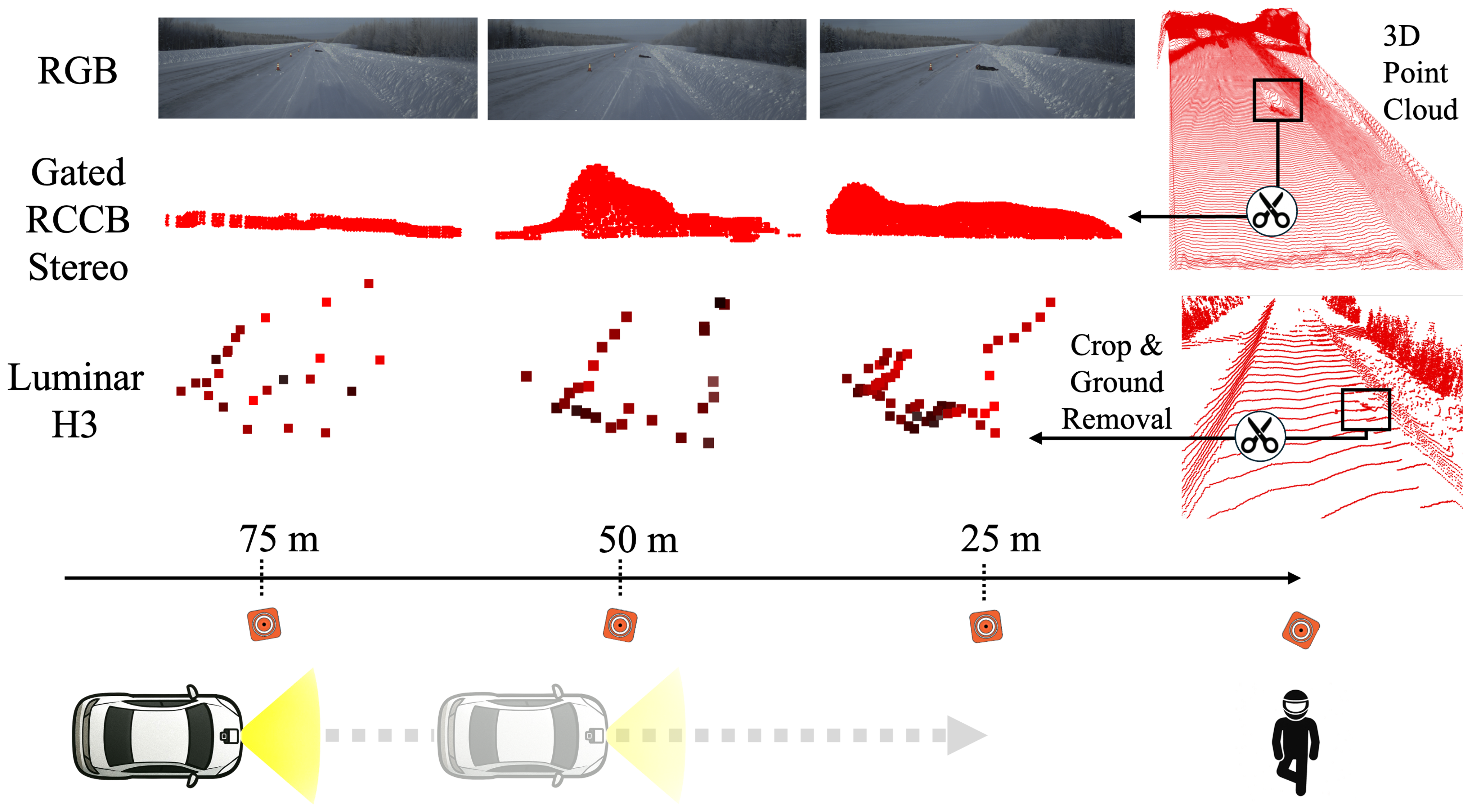
We record driving scenes in both summer and winter with lost-cargo obstacles—small, slightly elevated items—placed on the road at controlled long-range distances. Each scene is captured across multiple sensing modalities, including LiDAR and stereo-based depth estimation, and all outputs are mapped into 3D to enable consistent cross-sensor comparison.
Across these modalities, the reconstructed 3D structure of the same object can differ greatly: some systems produce dense geometry but smooth away small obstacles at distance, while others provide accurate range but sample too sparsely to preserve object shape. These effects are clearly visible in the data yet are not reflected by common depth metrics, which primarily evaluate global distance accuracy and are dominated by large planar regions.
2T2S Metric
To resolve this gap, we introduce 2T2S, a perceptual, modality-agnostic metric that evaluates how well a predicted point cloud preserves the geometric and semantic structure of each lost-cargo object. By comparing predictions to high-fidelity ground-truth meshes in a learned feature space, 2T2S captures object-level fidelity that existing metrics fail to measure.
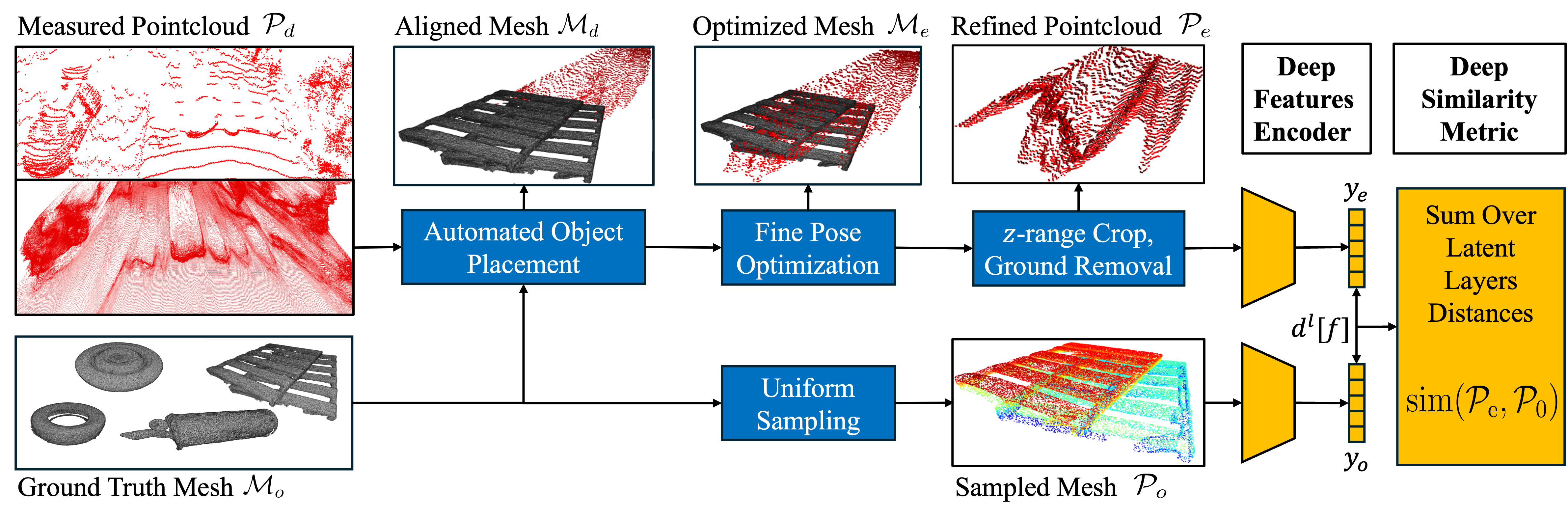
The figure above summarizes the 2T2S evaluation pipeline for assessing small, long-range obstacles across different sensing modalities. Starting from a measured point cloud Pd together with a high-fidelity ground-truth mesh for each lost-cargo object, we first place the mesh into the closest short-range capture (15m or 25m) to obtain a reliable initial pose. This reference alignment is then transferred to each evaluation distance using ICP, ensuring consistent object geometry across the full sequence.
Because long-range measurements are sparse and sensitive to small pose errors, we refine this alignment through a dedicated fine pose optimization that minimizes a weighted point-to-mesh objective. After alignment, we crop the measurement to isolate the object region and remove ground points, yielding the refined evaluation point cloud Pe. This ensures that evaluation focuses on the obstacle itself rather than being dominated by planar ground surfaces.
For computing the 2T2S metric, we uniformly sample the aligned ground-truth mesh to obtain P0, and feed both Pe and P0 through a shared point-cloud feature encoder. Intermediate feature activations from multiple layers are extracted, normalized, and compared in feature space; the aggregated discrepancy across layers forms the final 2T2S score. This produces a perceptual, modality-agnostic similarity measure that captures whether the reconstructed 3D structure preserves the semantic and geometric characteristics of the object, even under sparsity and incomplete observations.
Qualitative Results

The examples above demonstrate reconstructions from summer and winter scenes using different sensors. At long range and under varying environmental conditions, small lost-cargo objects are consistently difficult to recover in 3D. LiDAR sensors such as Luminar and Velodyne VLS-128 may register only a handful of returns on these tiny obstacles; despite this, conventional depth metrics can rate their predictions favorably because the few points they do observe are metrically accurate, even though the resulting geometry provides almost no usable shape information.
Image-based stereo and monocular methods show complementary failure modes: while they provide dense predictions, depth accuracy degrades with distance, causing small objects to collapse into the ground surface or disappear entirely. Across modalities and conditions, the reconstructions diverge significantly in how well they preserve object geometry, yet these differences are largely invisible to standard metrics dominated by road and background regions.
These observations further motivate the need for 2T2S: an evaluation method that captures object-level fidelity by comparing predicted point clouds to accurate ground-truth meshes in a perceptual feature space, rather than relying solely on global distance errors. This allows the evaluation to reflect the actual reconstruction quality of small obstacles that matter for safe autonomous navigation.
Metric Comparison
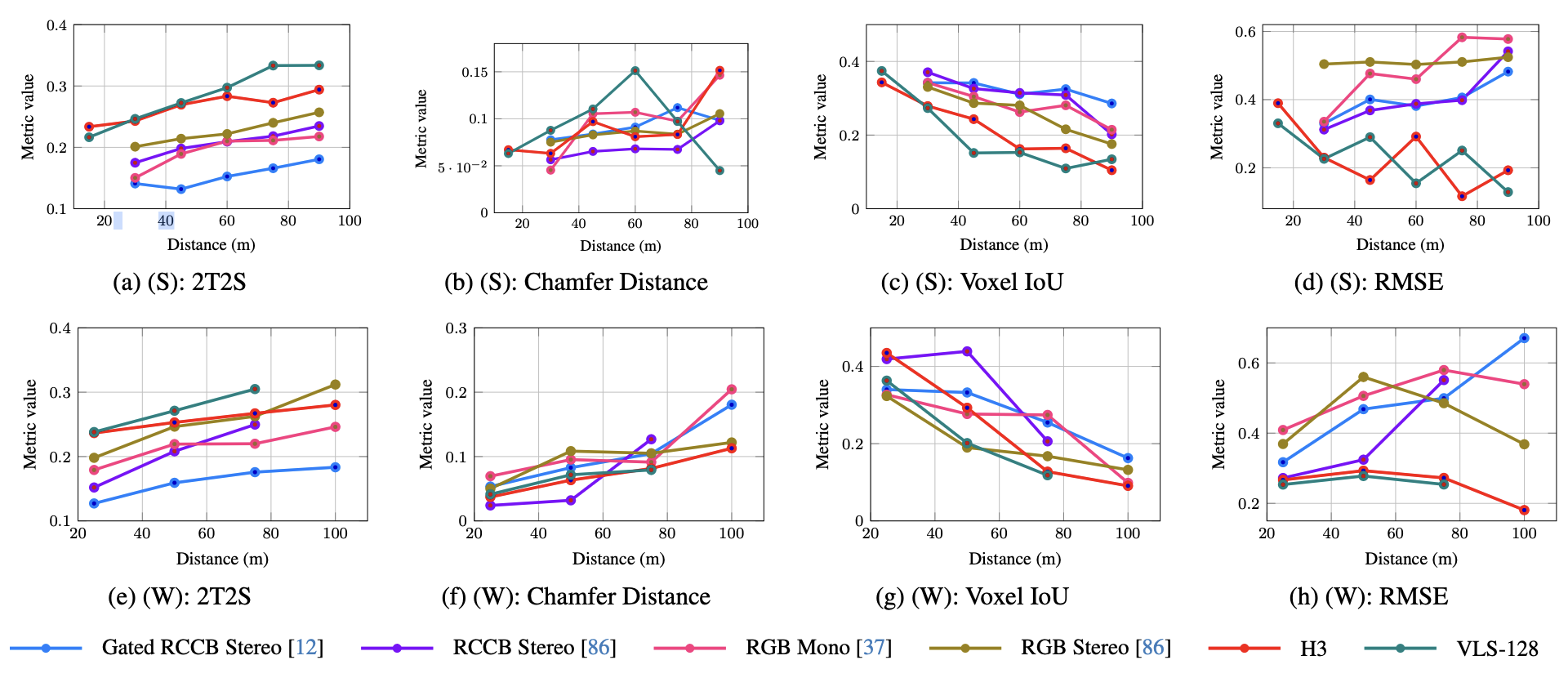
As shown above, the averaged, distance-binned evaluation results for all perception methods across both summer (S) and winter (W) recordings. As object distance increases, reconstruction quality diverges substantially across modalities; however, most standard depth metrics fail to reflect these differences in a consistent or meaningful way, frequently favoring LiDAR outputs because of precise but sparse range measurements that do not preserve object shape.
In contrast, the 2T2S metric aligns closely with the qualitative behavior observed in the data. By evaluating similarity in a learned feature space, 2T2S measures whether a reconstructed point cloud actually retains the geometric and semantic structure of a small, distant obstacle, rather than only matching its depth values on a few pixels or returns. This leads to stable and interpretable rankings across distances and conditions, with camera-based methods—particularly Gated RCCB Stereo—achieving the highest similarity to ground truth due to their ability to preserve object shape at long range.
These results demonstrate that 2T2S captures the cross-modality trade-offs between resolution and accuracy and provides a robust, object-level evaluation signal that existing depth metrics overlook. This makes 2T2S especially suitable for assessing reconstruction quality in safety-critical long-range perception scenarios.
Related Publications
[1] Samuel Brucker, Stefanie Walz, Mario Bijelic and Felix Heide.
Cross-spectral Gated-RGB Stereo Depth Estimation. The IEEE International Conference on Computer Vision (CVPR), 2024.
[2] Stefanie Walz, Andrea Ramazzina, Dominik Scheuble, Samuel Brucker, Alexander Zuber, Werner Ritter,
Mario Bijelic and Felix Heide.
A Multi-Modal Benchmark for Long-Range Depth Evaluation in Adverse Weather Conditions. The IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025.
[3] Tobias Gruber, Mario Bijelic, Felix Heide, Werner Ritter and Klaus Dietmayer.
Pixel-Accurate Depth Evaluation in Realistic Driving Scenarios. The International Conference on 3D Vision (3DV), 2019.