
All You Need is RAW:
Defending Against Adversarial Attacks with Camera Image Pipelines
ECCV 2022
Existing neural networks for computer vision tasks are vulnerable to adversarial attacks: adding imperceptible perturbations to the input images can fool these methods to make a false prediction on an image that was correctly predicted without the perturbation. Various defense methods have proposed image-to-image mapping methods, either including these perturbations in the training process or removing them in a preprocessing denoising step. In doing so, existing methods often ignore that the natural RGB images in today’s datasets are not captured but, in fact, recovered from RAW color filter array captures that are subject to various degradations in the capture.
In this work, we exploit this RAW data distribution as an empirical prior for adversarial defense. Specifically, we proposed a model-agnostic adversarial defensive method, which maps the input RGB images to Bayer RAW space and back to output RGB using a learned camera image signal processing (ISP) pipeline to eliminate potential adversarial patterns. The proposed method acts as an off-the-shelf preprocessing module and, unlike model-specific adversarial training methods, does not require adversarial images to train. As a result, the method generalizes to unseen tasks without additional retraining. Experiments on large-scale datasets for different vision tasks validate that the method significantly outperforms existing methods across task domains.
Existing defense approaches learn an RGB-to-RGB projection from an adversarial distribution Y to its natural RGB distribution Y’. In contrast, our approach learns a mapping via the intermediate natural RAW distribution X, which is achieved by three specially designed operators: F : Y’ → X, G : X → Y , and S : X → Y .
Paper
Yuxuan Zhang, Bo Dong, Felix Heide
All You Need is RAW: Defending Against Adversarial Attacks with Camera Image Pipelines
ECCV 2022
Method Overview
Departing from existing methods, we learn a mapping from Y’
to Y via an intermediate RAW distribution, X, which incorporates these RAW statistics of natural images, such as sensor photon counts, multispectral color filter array distributions and optical aberrations. To this end, the approach leverages three specially designed operators: F : Y’ → X, G : X → Y , and S : X → Y. Specifically, the F operator is a learned model, which maps an adversarial sample from its adversarial distribution to its corresponding RAW sample in the natural image distribution of RAW images. Operator G is another learned network that performs an ISP reconstruction task, i.e., it converts a RAW image to an RGB image. The operator S, however, is a conventional ISP, which is implemented as a sequence of cascaded software-based sub-modules. In contrast to operator F, operator S is non-differentiable. For defending against an attack, the proposed approach first uses the F operator to map an input adversarial image, I’, to its intermediate RAW measurements, IW . Then, IW is processed separately by the G and S operators to convert it to two images in the natural RGB distribution, denoted as as IG and IS, respectively. Finally, our method outputs a benign image, I, in the natural RGB distribution by combining IG and IS in a weighted-sum manner.
RAW-to-RGB Network Details
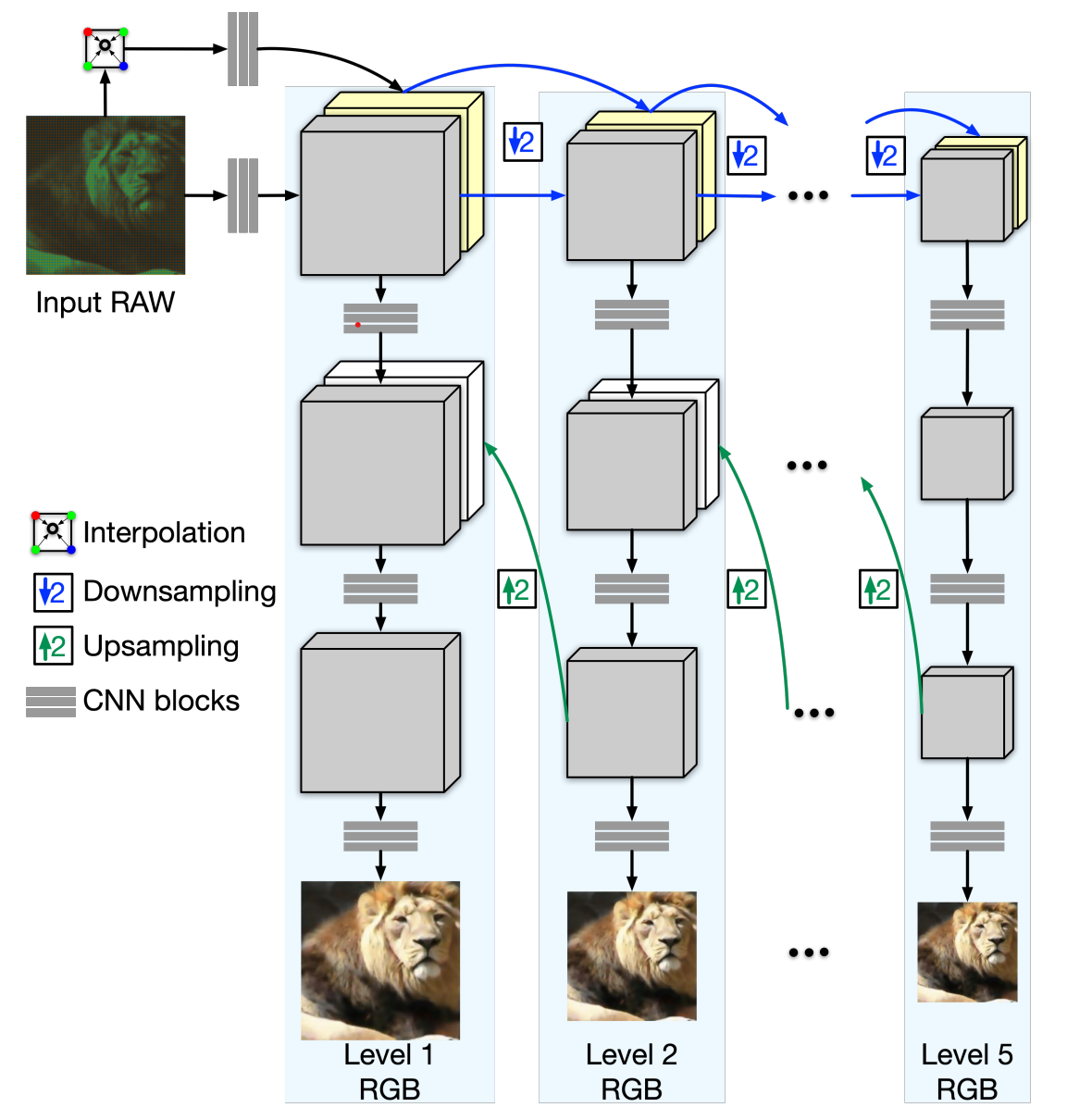
The G operator is represented by a neural network that converts the IW generated by the F operator to an RGB image. During this process, we aim to guide local adjustment with global contextual information. This motivates us to devise a pyramidal convolutional neural network to fuse global and local features. To this end, we propose a variant of PyNet consisting of five levels. Here, the 1st level is the finest, and the 5th level is the coarsest. The finer levels use upsampled features from the coarser levels by concatenating them. We modify PyNet by adding an interpolation layer before the input of each level, interpolating the downsampled RAW Bayer pattern. This facilitates learning as the network only needs to learn the residuals between interpolated RGB and ground truth RGB.
The loss function for this model consists of three components: perceptual, structural similarity, and L2 loss. As the model is trained in a coarse-to-fine manner, different losses are used for each level.
Qualitative Results

Qualitative outputs of the proposed method and state-of-the-art defense methods on the ImageNet dataset, which underlines the motivation of combining the proposed G and S operators in a weighted sum manner. The G operator learns to mitigate the adversarial pattern, i.e., it recovers a latent image in the presence of severe measurement uncertainty, while the S operator can faithfully reconstruct high-frequency details. Note that our method is able to generalize well to images from the ImageNet dataset, which typically depict single objects, although it is trained on the Zurich-Raw-to-RGB dataset, consisting of automotive street scenes.
Quantitative Results
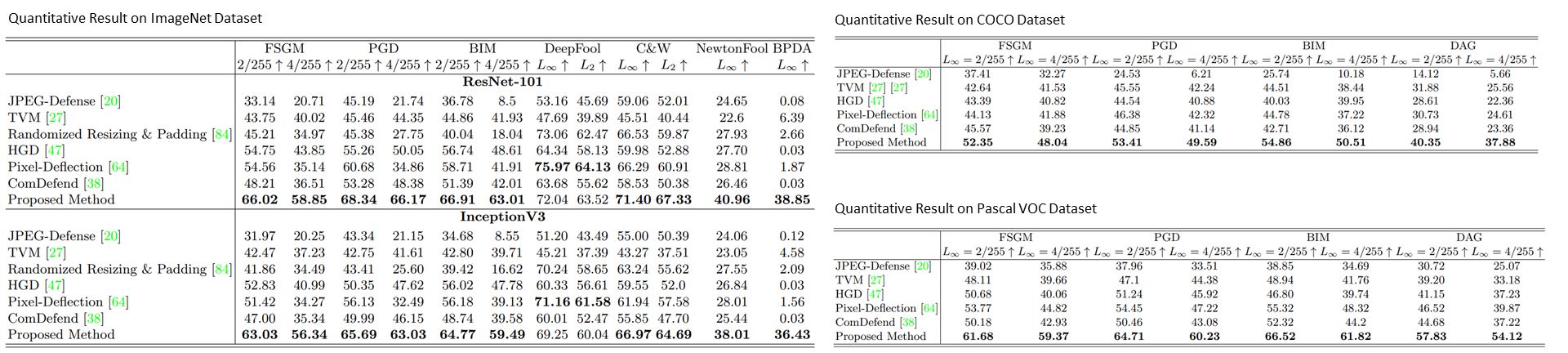
Quantitative Comparisons: We evaluate Top-1 Accuracy on the ImageNet dataset for the image classification task and compare the proposed method to existing input-transformation methods. The best Top-1 accuracies are marked in bold. Our defense method offers the best performance in all settings. We also evaluate the defense method for the object detection task on COCO and the semantic segmentation task on Pascal VOC.
We evaluate the defense methods against commonly used adversarial attack algorithms, namely FGSM, BIM, DeepFooL, PGD, C&W, and NewtonFool. The Top-1 classification accuracies of all methods are reported in the Table. Our approach outperforms the baseline methods with a large margin under all experimental settings except those with DeepFool attacks. Notably, under DeepFool attacks, the differences between the best performer pixel-deflection and ours are marginal. Moreover, with PGD and BIM attacks, our defense method offers the lowest relative performance degradation when the more vigorous attack is performed (i.e., maximum perturbation increases from 2/255 to 4/255). The qualitative results above underline the motivation of combining G and S operators in a weighted sum manner. The G operator learns to mitigate the adversarial pattern, i.e., it recovers a latent image in the presence of severe measurement uncertainty, while the S operator can faithfully reconstruct high-frequency details.
Related Publications
[1]Buu Phan, Fahim Mannan, Felix Heide. Adversarial Imaging Pipelines. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
[2] Steven Diamond, Vincent Sitzmann, Frank Julca-Aguilar, Stephen Boyd, Gordon Wetzstein, Felix Heide. Dirty Pixels: Towards End-to-End Image Processing and Perception. ACM Transactions on Graphics (SIGGRAPH) 2021
[3] Ethan Tseng, Ali Mosleh, Fahim Mannan, Karl St-Arnaud, Avinash Sharma, Yifan Peng, Alexander Braun, Derek Nowrouzezahrai, Jean-François Lalonde, and Felix Heide. Differentiable Compound Optics and Processing Pipeline Optimization for End-to-end Camera Design. ACM Transactions on Graphics (SIGGRAPH) 2021
[4] Ali Mosleh, Avinash Sharma, Emmanuel Onzon, Fahim Mannan, Nicolas Robidoux, Felix Heide. Hardware-in-the-loop End-to-end Optimization of Camera Image Processing Pipelines. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020