
Seeing Through Fibers: Unsupervised Image Reconstruction in Fiber Bundle Imaging Systems
- Amir Reza Vazifeh
- Congli Wang
- Amogh Joshi
- Ilya Chugunov
- Jipeng Sun
- Jiwoon Yeom
- Jason W. Fleischer
-
José S. Pulido
- Felix Heide
Optics Express 2026
Fiber bundle imaging methods capture images via bundles of fibers directed to a sensor. Existing systems suffer from sampling artifacts such as honeycomb patterns due to their discrete and non-uniform fiber layout, fundamentally limiting image resolution. Conventional reconstruction methods rely on precise calibration of the fiber layout or learning from paired datasets, both of which have limited generalization across imaging setups and require sample-specific preparation. We present an unsupervised method for reconstructing high-resolution images using a burst of misaligned frames that does not require known fiber layout, paired training data, or per-sample calibration. Our approach jointly solves motion estimation and image reconstruction through test-time training. We model each burst frame as a deformed observation of a single canonical view, parameterizing the underlying motion with a coordinate-based network. A second coordinate-based network learns a joint super-resolved scene representation shared across aligned frames. Both networks are trained jointly end-to-end without paired ground truth or external supervision. Simulation and experimental results demonstrate that our method robustly removes fiber bundle artifacts and generalizes to various sample types.
Seeing Through Fibers: Unsupervised Image Reconstruction in Fiber Bundle Imaging Systems
Amir Reza Vazifeh, Congli Wang, Amogh Joshi, Ilya Chugunov, Jipeng Sun, Jiwoon Yeom, Jason W. Fleischer, José S. Pulido, and Felix Heide
Optics Express 2026
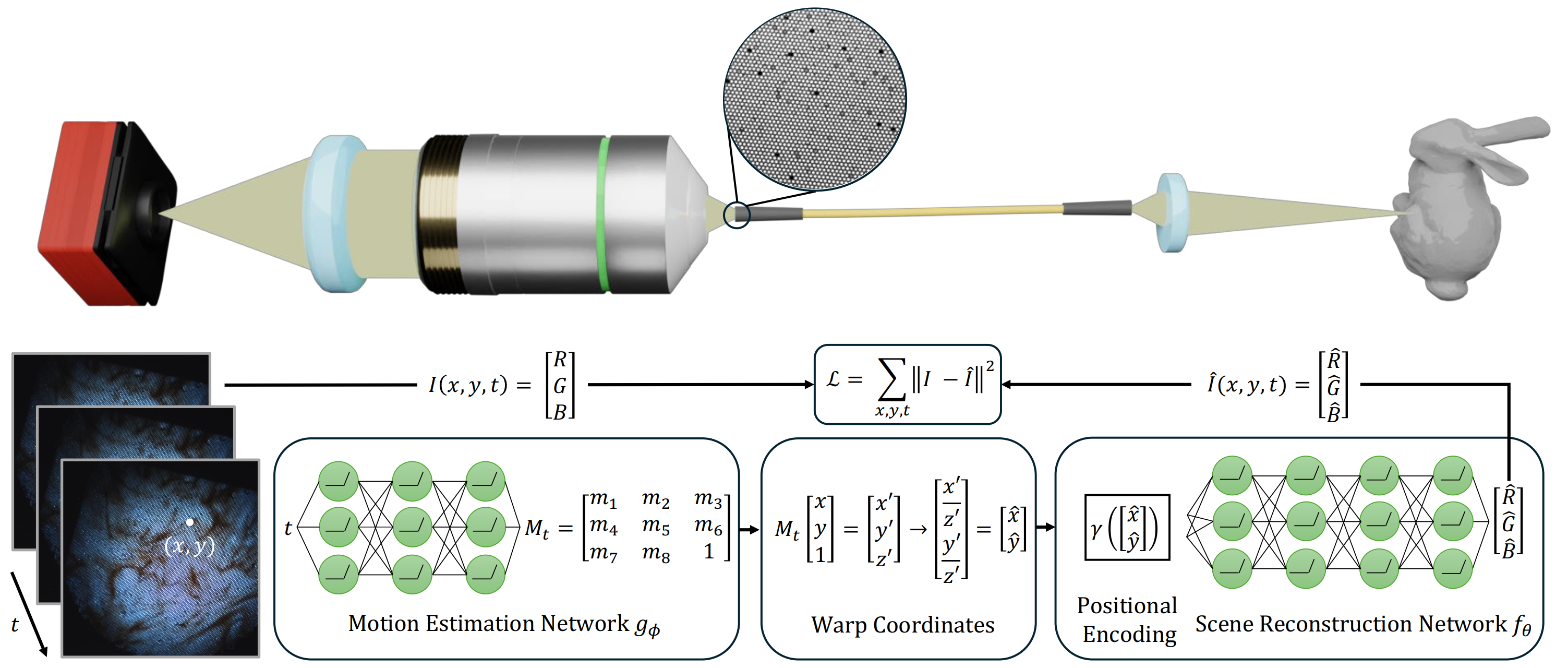
Fiber bundle capture and reconstruction. Moving objects are captured through a lens, transmitted via a fiber bundle, and magnified by secondary optics, resulting in a burst of misaligned frames with structured artifacts. To address this, our method uses two coordinate-based MLPs trained jointly. The first network models inter-frame motion by estimating the parameters of a homography transformation, aligning all frames into a common canonical coordinate system. The second network represents the underlying scene as a continuous function that maps spatial coordinates to RGB values, enabling the synthesis of a clean, high-resolution image. To better capture fine details and overcome the spectral bias of MLPs, the aligned coordinates are first transformed using positional encoding before being passed to the scene network. After training, the model reconstructs artifact-free frames by querying the learned representation at any desired spatial and temporal coordinates, effectively aggregating information across the entire burst.
Simulated Dataset and Synthetic Evaluation
For the simulated data, random Brownian motion was applied to a raw image to generate a sequence of 20 frames. Each frame was then multiplied by a fiber mask to mimic the imaging characteristics of a fiber bundle. The results of our algorithm on two simulated captures are shown below.
Experimental Evaluation
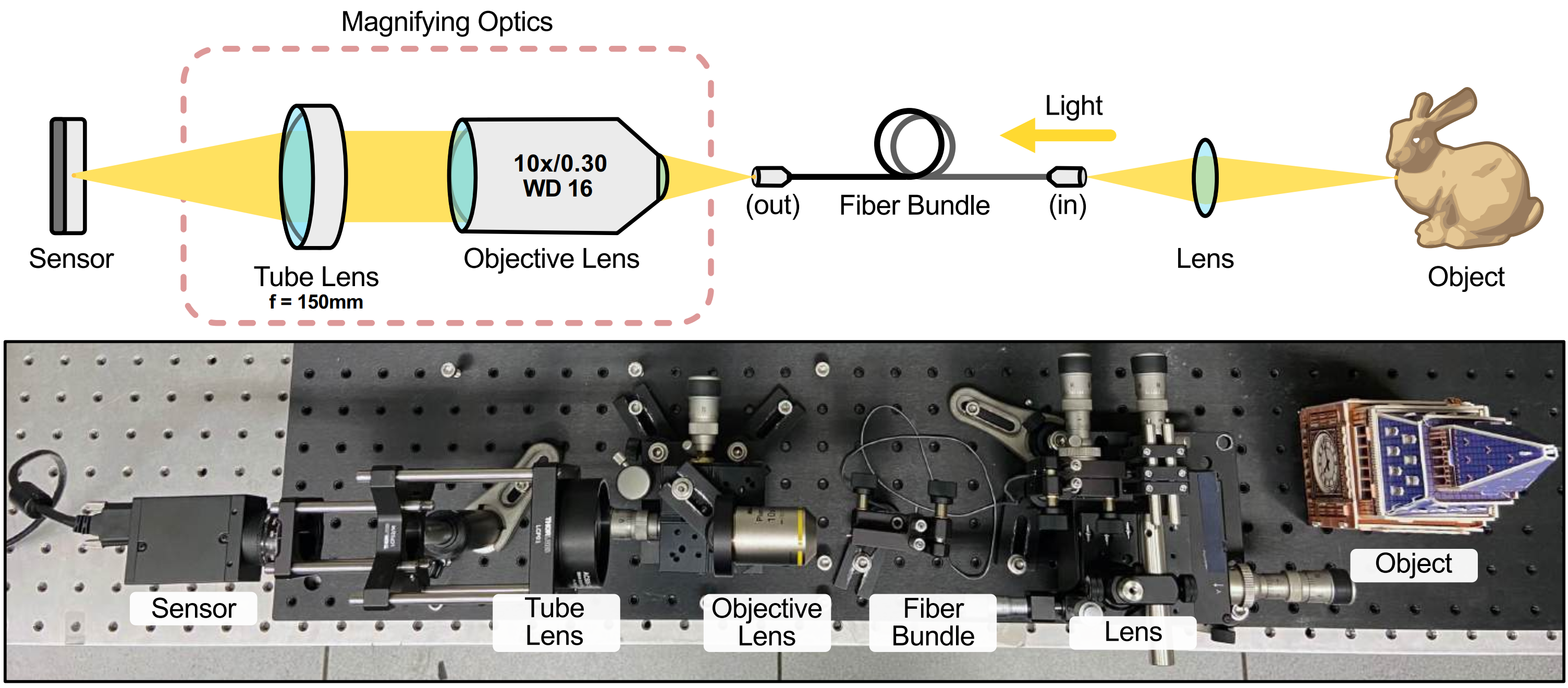
For experimental validation, we used a fiber bundle imaging system employing a lens (38° FOV) coupled to a SCHOTT fiber bundle that relays the object image through a 10× Nikon objective lens and achromatic doublet to a color image sensor. We displayed a set of images on a screen and applied random motion to generate a 20-frame video. These frames were then imaged using our setup. Our reconstruction reveals structural details that are not visible in the experimental captures, such as white spots on the orange butterfly wings and vascular structures in the tissue sample. To evaluate robustness under different fiber configurations, we also applied our method to an image burst of the 1951 USAF resolution chart from PyFiberBundle. While the raw image already resolves Group 7 Element 1, our reconstruction further extends resolution to Group 7 Element 5, achieving approximately 1.59× improvement in resolution.
Related Publications
[1] Ilya Chugunov, David Shustin, Ruyu Yan, Chenyang Lei, Felix Heide. Neural Spline Fields for Burst Image Fusion and Layer Separation. CVPR 2023