
UniLiPs: Unified LiDAR Pseudo-Labeling with Geometry-Grounded Dynamic Scene Decomposition
- Filippo Ghilotti
- Samuel Brucker
-
Nahku Saidy
-
Matteo Matteucci
- Mario Bijelic
- Felix Heide
3DV 2026
Unlabeled LiDAR logs, in autonomous driving applications, are inherently a gold mine of dense 3D geometry hiding in plain sight – yet they are almost useless without human labels, highlighting a dominant cost barrier for autonomous-perception research. In this work we tackle this bottleneck by exploiting temporal and geometric consistency across LiDAR sweeps to lift cues from text and 2D vision foundation models directly into 3D, with no manual input, to introduce an unsupervised multi-modal pseudo-labeling method that leverages geometric priors from temporally accumulated LiDAR maps and an iterative update rule that enforces joint geometric–semantic consistency while detecting moving objects via inconsistencies. Our method jointly produces 3D semantic labels and 3D bounding boxes, with human-like quality, and densified LiDAR scans that improve existing models depth prediction MAE by 51.5% in the 80–150 meters range and 22.0% in the 150–250 meters range.
UniLiPs
From a set of raw images, a set of LiDAR scan and IMU measurements, we first generate 2D semantic masks with our by pseudo labeling engine and project them into 3D space through LiDAR projection. We then integrate them into an accumulated map generated by a SLAM method, while simultaneously removing moving points identified through a lightweight segmentation network. To obtain a refined static scene map we first propagate the labels through geometric and temporal constraints and later on exploit them to remove remaining floaters and outliers (in red) through our Iterative Weighted Update Function.
Pseudo Labeling Engine
Given a set of RGB images, our psuedo labeling engine predicts a per‑pixel label mask. Each frame is down‑sampled and processed with SAM2, producing a set of object masks. The input image is segmented by three separate OneFormer models, individually trained on COCO, ADE20K and Cityscapes. For each mask, the initial proposal list is generated by stacking the most recurrent class from each OneFormer model per-pixel logit maps. We then extract three image crops centered on the mask’s bounding box: original size, large, and huge. Subsequently, open-vocabulary classification is performed by non-prompted BLIP on the large patch, proposing class candidates that augment the OneFormer proposal list. CLIP re‑ranks the candidates list on a tighter crop, producing a shortlist of the top-3 keywords. CLIPSeg processes the hugw crop together with this shortlist and outputs per‑pixel scores. A majority vote assigns the final class to all pixels of the small patch, reducing boundary noise. If multiple classes remain, we keep the one with the highest pixel count. Iterating through every patch we obtain a refined label map.
Label Reweighting
Our method accumulates semantic observations across multiple timestamps and propagates labels probabilistically throughout the map, yielding highly reliable semantic and geometric information. Consequently, even if an object is mislabeled in a single frame, we can recover the correct semantic label by re-evaluating it against the map once sufficient consistent observations have been integrated, ensuring strong temporal stability across frames. For example, a traffic sign may be misclassified as fence at time t, but integrating observations from neighboring frames, the accumulated evidence corrects the mistake, and the proper label is recovered through majority voting.
UniLiPS Qualitative Outputs
After the refinement stage, our pipeline can generate different pseudo ground‑truth supervision signals like densified LiDAR scans, 360 degrees semantic labels and 3D bounding boxes from moving‑object segmentation masks.
We extract semantic labels for each LiDAR scan from the semantically propagated map, preserving the initial guess for points without correspondence.
We transform the moving object detections into bounding boxes, by clustering them and fitting the minimum enclosing cuboid to each cluster, assigning a minimum size; we use PCA to get an initial estimate of the yaw and use a Kalman Filter based tracker, with constant velocity model including yaw dynamics. We then refine each object trajectory using a spline optimization method.
Further we provide high resolution LiDAR frames from the accumulated map, exploiting the pose to reintroduce moving objects corresponding to that specific pose and time, and compensate for occlusions with our Adaptive Spherical Occlusion Culling. We show qualitative examples in the video below.
Pseudo Labels Quality: Depth Estimation
Our high-resolution LiDAR frames, with three to five times the density across all ranges, can serve as reference data (ground truth) for depth learning from images. To demonstrate this, for pseudo-depth, we finetune an NMRF model on the KITTI dataset (short-range LiDAR + small-baseline stereo) and on our Long Range highway dataset (long-range LiDAR + wide-baseline cameras). In the table on the right, we demonstrate that a lightweight fine-tuning on a subset of our consistent pseudo–ground-truth leads to substantial gains: on average, MAE on both KITTI and our newly introduced long-range dataset is reduced by 51.5% in the 80–150 m range and by 22.0% in the 150–250 m range. These gains are not replicated when the fine-tuning is performed using pseudo-depth frame inferred from state-of-the-art monocular and stereo foundation models, or when using a simple accumulated LiDAR ground-truth (LIO-SAM) without our floaters and occlusion refinement steps, highlighting the importance of these two steps in our pipeline.
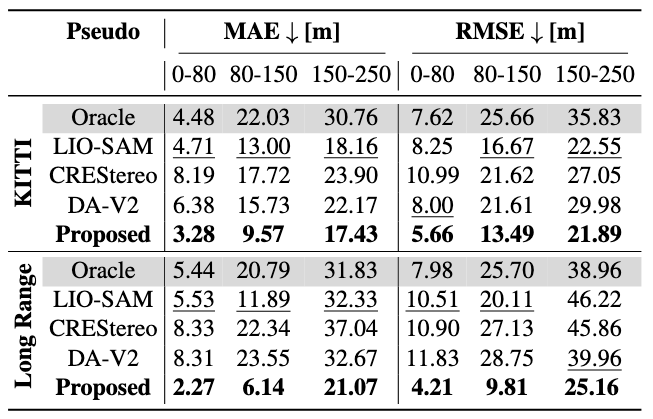
Depth Estimation Results on KITTI (top) and Long Range Dataset (bottom)
Pseudo Labels Quality: Semantic Segmentation
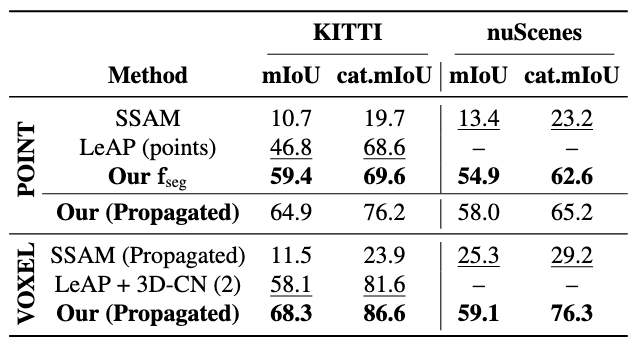
Pseudo Labels Quality on KITTI and NuScenes
In the table on the left, we evaluate our semantic pseudo-labels on SemanticKITTI validation sequence 08 and on more than 40 thousands samples of NuScenes, generating them using only the front-left camera for the former and all six cameras for the latter. We evaluate and compare our pseudo labels against LeAP and Semantic SAM: for a fair comparison we as well consider only labeled points and reduce the number of classes to a set of 11 classes. Results highlight how our pseudo labeling function is the most accurate in labeling LiDAR data. To further compare with LeAP, which propagates its initial labels on a 0.2 meters voxel grid, we voxelize our propagated labels at the same resolution and compare with the reported best result. Thanks to the higher point-level accuracy of our propagation technique, our voxelized predictions outperform all competing methods.
In the table on the right, we then train a PVKD model on a mix of ground-truth and pseudo labels. We keep all hyperparameters fixed and vary only the supervision source: in the Oracle case we use 100% ground-truth labels; for Limited GT a randomly chosen 10% ground-truth subset; for Our we feed that identical 10% subset plus 90% pseudo labels generated by our pipeline. We follow the same procedure and train PVKD on a 10-90 mix of ground truth and pseudo labels generated using state of the art methods like Semantic SAM, Lasermix and a pre-trained Cylinder3D model (simulating automatic labeling). Our pseudo labels achieve near-oracle performance, with a mean mIoU gap of just 1.09%, or 0.30% when excluding classes not predicted by our method. Notably, ours is the only approach that operates successfully in the 0–100 regime where competing baselines still require some ground-truth input.
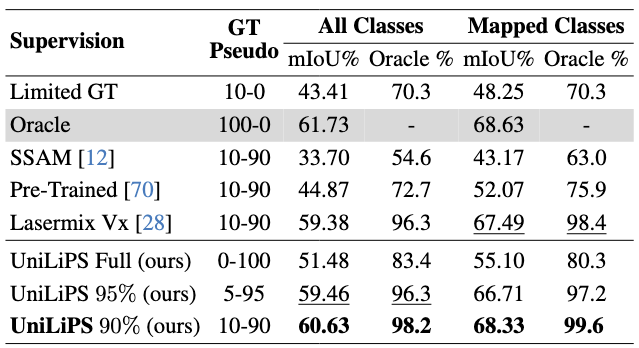
Semantic Segmentation Results of PVKD on KITTI
Pseudo Labels Quality: Object Detection

Pseudo Bounding Boxes Quality on Long Range Dataset
In the table on the left, We evaluate our pseudo bounding boxes performance on our highway long range dataset on a maximum range of 250 meters. We compare them with LISO, due to the similar detection-trajectory-refinement methodology, and ICP-Flow, an annotation-free pseudo-labeling method, showing the higher quality of our detections.
In the table on the right, following what done for the other pseudo labels, we train an off-the-shelf detector like PointPillars, using either 100% ground truth labels (Oracle) or a 20/80 ground-truth–pseudo mix generated by our method or by ICP-Flow. Due to higher quality and lower noise injected, our pseudo labels deliver near-oracle performance, outperforming the tested alternative pseudo-labeling techniques.
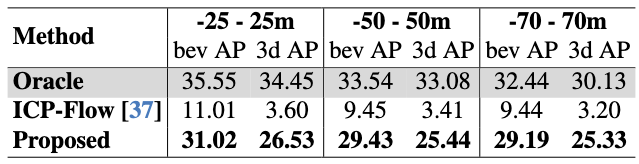
Object Detection Results on Long Range Dataset
Related Publications
[2] Stefan Baur, Frank Moosmann, and Andreas Geiger. LISO: Lidar-only self-supervised 3d object detection. ECCV 2024
[12] Jiaqi Chen, Zeyu Yang, and Li Zhang. Semantic-Segment-Anything. 2023
[37] Yancong Lin and Holger Caesar. Icp-flow: Lidar scene flow estimation with icp. CVPR 2024