
Flow-Guided Online Stereo Rectification for Wide Baseline Stereo
-
Anush Kumar
- Fahim Mannan
- Omid Hosseini Jafari
- Shile Li
- Felix Heide
CVPR 2024

Stereo rectification is widely considered "solved'' due to the abundance of traditional approaches to perform rectification. However, autonomous vehicles and robots in-the-wild require constant re-calibration due to exposure to various environmental factors, including vibration, and structural stress, when cameras are arranged in a wide-baseline configuration. Conventional rectification methods fail in these challenging scenarios: especially for larger vehicles, such as autonomous freight trucks and semi-trucks, the resulting incorrect rectification severely affects the quality of downstream tasks that use stereo/multi-view data. To tackle these challenges, we propose an online rectification approach that operates at real-time rates while achieving high accuracy. We propose a novel learning-based online calibration approach that utilizes stereo correlation volumes built from a feature representation obtained from cross-image attention. Our model is trained to minimize vertical optical flow as proxy rectification constraint, and predicts the relative rotation between the stereo pair. The method is real-time and even outperforms conventional methods used for offline calibration, and substantially improves downstream stereo depth, post-rectification. We release two public datasets, a synthetic and experimental wide baseline dataset, to foster further research.
Paper
Flow-Guided Online Stereo Rectification for Wide Baseline Stereo
Anush Kumar, Fahim Mannan, Omid Hosseini Jafari, Shile Li, Felix Heide
CVPR 2024
Flow-Guided Online Rectification
We divide our pipeline into several simpler sub-modules, each sub-module is designed to contribute to the rectification task. Here we describe the motivation behind these sub-modules. The model operates on a pair of images which are fed to a shared CNN ((a) Feature Extraction) to extract shift-equivariant features. The features are then rectified using a prior pose estimate which can either be from previous estimation or set to identity. This is followed by our feature enhancement step ((b) Feature Enhancement), which comprises of a positional embedding step and a transformer encoder. The transformer encoder captures global information across both views using self-attention and cross-attention. Next, we employ a correlation volume, ((c) Correlation Volume), to establish matches based on the features extracted from the transformer encoder. The volume represents a match distribution for every pixel in the feature map. The correlation volume is then processed by a decoder to implicitly learn to discern noisy matches and predict a simplified rotation estimate, which undergoes further processing to produce the final relative rotation prediction. Given our rotation prediction, we rectify the input images and estimate the optical flow. With this flow estimate in hand, we minimize the vertical flow, ((d) Loss Calculation).
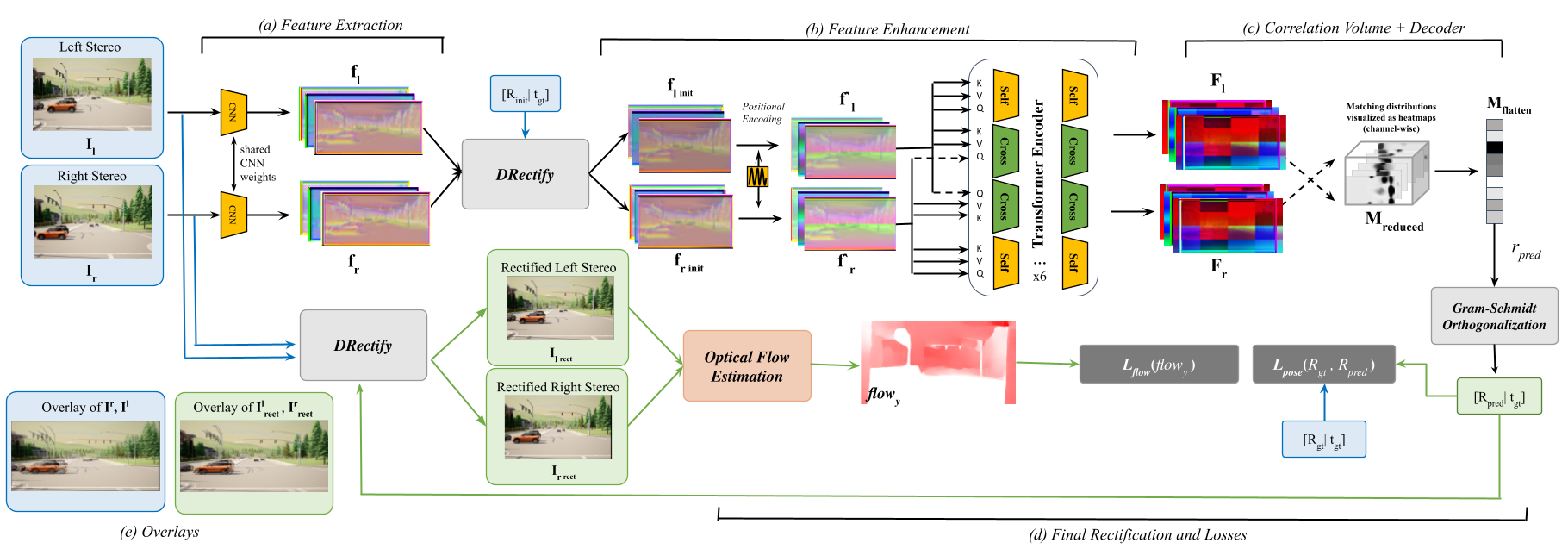
Flow-Guided Online Rectification We breakdown our model into sub-modules as described in this figure. (a) Feature Extraction, (b) Feature Enhancement in, and (c) Correlation Volume, Decoder and (d) Loss calculation. (e) The overlays are a simple illustration to understand the rectification quality, this is generated by a weighted addition of the stereo pairs.
Qualitative Results
Semi-Truck Highway The top row shows the overlay of the rectified left-right stereo pairs. Each column represents a different rectification method. To visually evaluate the rectification quality, focus on an object in the scene and compare the vertical disparity. Every row is accompanied by the corresponding depth inferred from HITNet.
Semi-Truck Urban The top row shows the overlay of the rectified left-right stereo pairs. Each column represents a different rectification method. To visually evaluate the rectification quality, focus on an object in the scene and compare the vertical disparity. Every row is accompanied by the corresponding depth inferred from HITNet.
Related Publications
[1] Stefanie Walz, Mario Bijelic, Andrea Ramazzina, Amanpreet Walia, Fahim Mannan and Felix Heide. Gated Stereo: Joint Depth Estimation from Gated and Wide-Baseline Active Stereo Cues The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR), 2023.
[2] Tobias Gruber, Frank D. Julca-Aguilar, Mario Bijelic, Werner Ritter, Klaus Dietmayer, and Felix Heide. Gated2depth: Real-time Dense Lidar from Gated Images The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR), 2019.