
Learned Feature Embeddings for Non-Line-of-Sight Imaging and Recognition
SIGGRAPH Asia 2020
We learn feature embeddings for non-line-of-sight imaging and recognition by propagating features through physical modules.
Objects obscured by occluders are considered lost in the images acquired by conventional camera systems, prohibiting both visualization and understanding of such hidden objects. Non-line-of-sight methods (NLOS) aim at recovering information about hidden scenes, which could help make medical imaging less invasive, improve the safety of autonomous vehicles, and potentially enable capturing unprecedented high-definition RGB-D data sets that include geometry beyond the directly visible parts. Recent NLOS methods have demonstrated scene recovery from time-resolved pulse-illuminated measurements encoding occluded objects as faint indirect reflections. Unfortunately, these systems are fundamentally limited by the quartic intensity fall-off for diffuse scenes. With laser illumination limited by eye-safety limits, recovery algorithms must tackle this challenge by incorporating scene priors. However, existing NLOS reconstruction algorithms do not facilitate learning scene priors. Even if they did, datasets that allow for such supervision do not exist, and successful encoder-decoder networks and generative adversarial networks fail for real-world NLOS data. In this work, we close this gap by learning hidden scene feature representations tailored to both reconstruction and recognition tasks such as classification or object detection, while still relying on physical models at the feature level. We overcome the lack of real training data with a generalizable architecture that can be trained in simulation. We learn the differentiable scene representation jointly with the reconstruction task using a differentiable transient renderer in the objective, and demonstrate that it generalizes to unseen classes and unseen real-world scenes, unlike existing encoder-decoder architectures and generative adversarial networks. The proposed method allows for end-to-end training for different NLOS tasks, such as image reconstruction, classification, and object detection, while being memory-efficient and running at real-time rates. We demonstrate hidden view synthesis, RGB-D reconstruction, classification, and object detection in the hidden scene in an end-to-end fashion.
Paper
Wenzheng Chen*, Fangyin Wei*, Kyros Kutulakos, Szymon Rusinkiewicz, Felix Heide
(* indicates equal contribution)
Learned Feature Embeddings for Non-Line-of-Sight Imaging and Recognition
SIGGRAPH Asia 2020
Video Summary
Selected Results
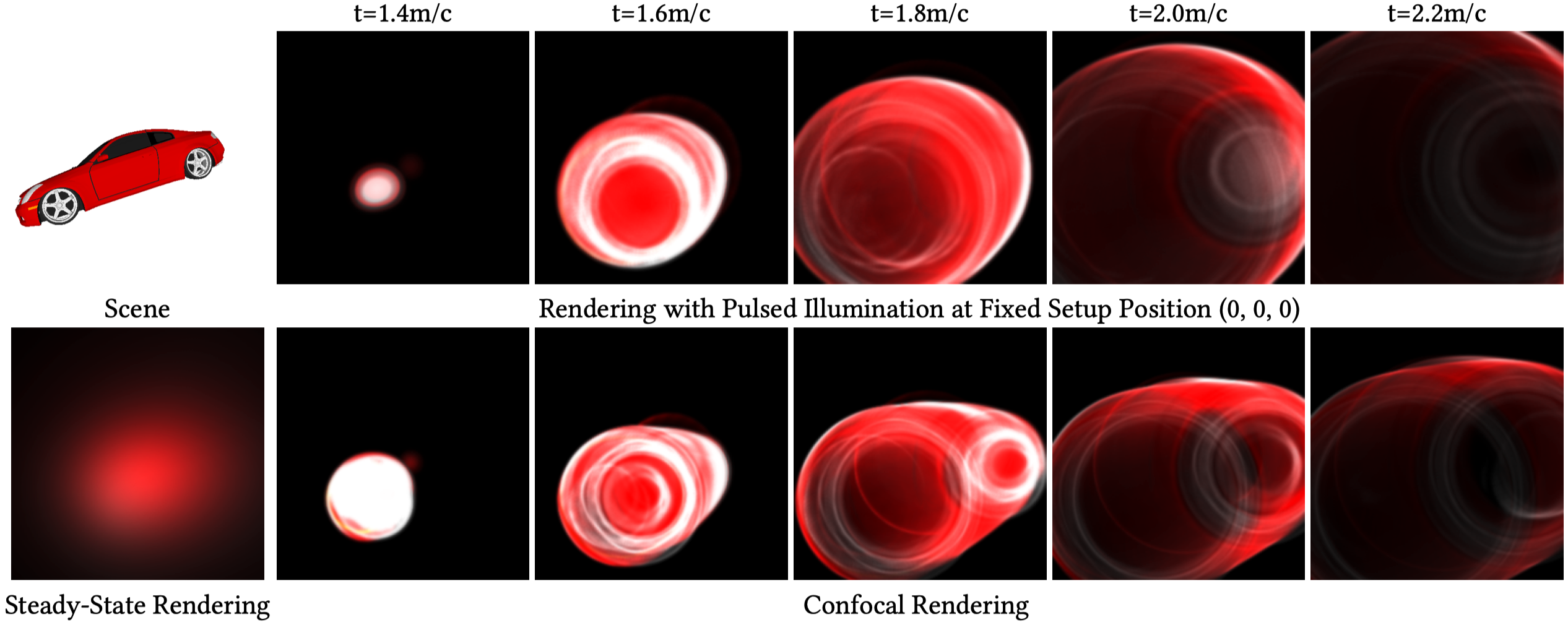
Transient Rasterization
Our rendering pipeline renders transient images using hardware-accelerated rasterization, supports confocal and nonconfocal setups and allows to render steady-state indirect reflections. To illustrate quality of the rendered transients we show images without the proposed detector noise model. Our approach renders a car model with 52081 vertices and 200018 faces to full transient measurement cubes with 256 × 256 × 600 spatio-temporal resolution at interactive rates on consumer GPU hardware within 117ms. Given scene (top left), we show the synthesized transient video frames at different travel times (right 5 columns). Top: transient images illuminated in a setup with a single pulsed light source at (0, 0, 0). Bottom: transient images in a confocal setup. The steady-state rendering without time resolution is shown in the bottom left.

Qualitative Evaluation for NLOS 2D Imaging
Compared to F-K [Lindell et al. 2019b], LCT [O’Toole et al. 2018a], and filtered back-projection (FBP) [Velten et al. 2012] (unmodified code from [Lindell et al. 2019b] for all comparisons), we observe that the proposed method is able to reconstruct 2D images with clearer boundaries while achieving more accurate color rendering. For example in the first column, the proposed model is able to reconstruct details on the front surface while F-K fails to recover fine details and LCT outputs a much blurrier estimates.

Generalization to Unseen Classes
We note that the proposed model, trained only on motorbikes, not only faithfully reconstructs unseen motorbikes (left), but also generalizes well on other unseen classes (right). We observe that even thin structures can be recovered well by the proposed method, e.g., the first lamp and the antenna on the fourth watercraft.
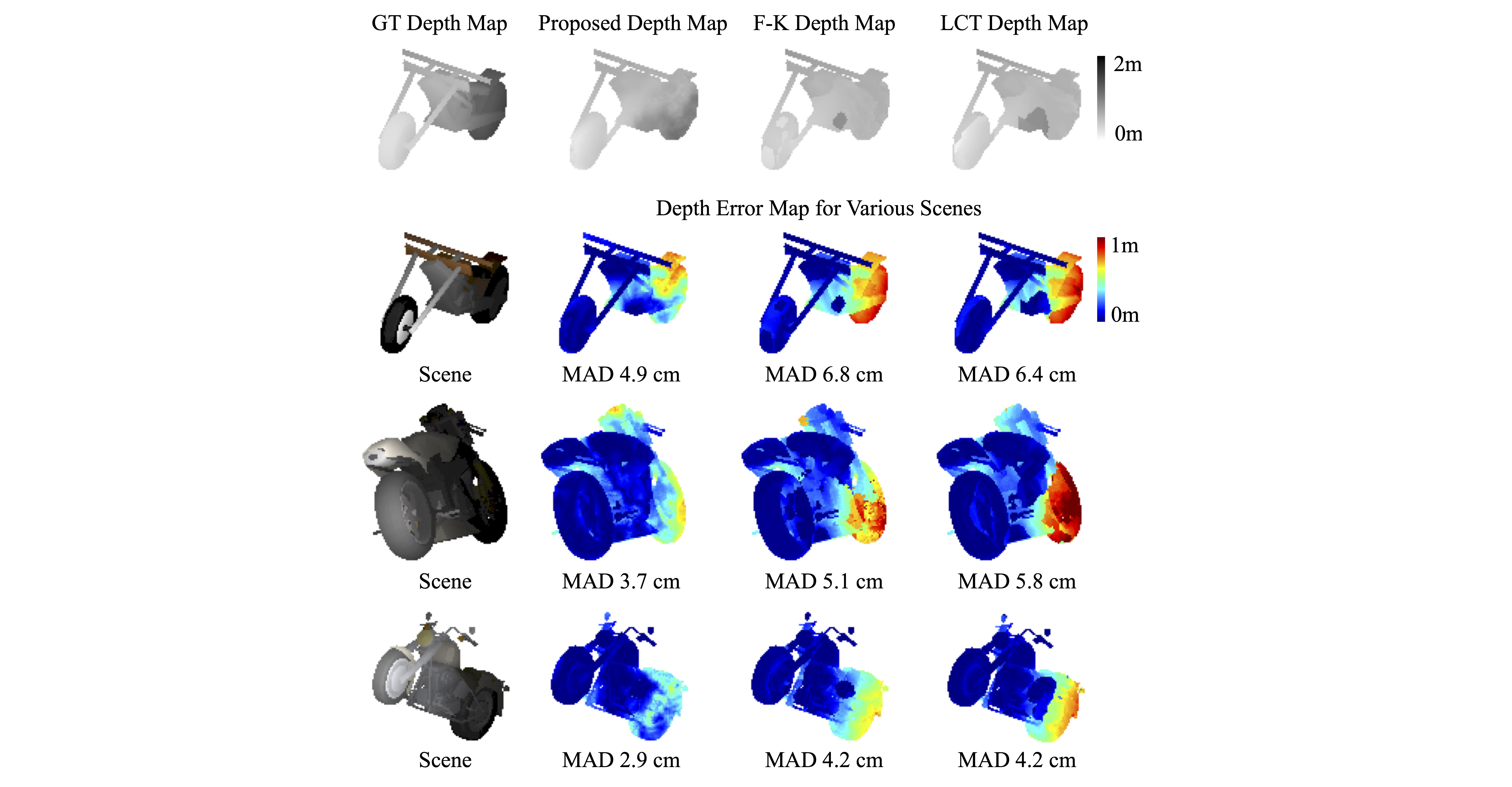
Depth Prediction
We visualize the error in depth prediction of a synthetic motorbike and compute Mean Absolute Distance (MAD) for each method. Our method predicts more accurate depth compared to the F-K and LCT methods, especially in challenging model parts that are distanced further from the relay wall.

Reconstructions from Pulsed Single-Photon Measurements
The proposed learned reconstruction method, trained only on synthetic motorbike dataset, generalizes to transient measurements acquired with the setup described in F-K [Lindell et al. 2019b]. The network handles challenging scenes with complex geometries, occlusions, and varying reflectance. Validating the synthetic assessment, the proposed learned method recovers fine hidden detail, especially with low reflectance, without amplifying reconstruction noise, outperforming existing methods qualitatively and quantitatively.