
Gated Fields: Learning Scene Reconstruction from Gated Videos
Reconstructing outdoor 3D scenes from temporal observations is a challenge that recent work on neural fields has offered a new avenue for. However, existing methods that recover scene properties, such as geometry, appearance, or radiance, solely from RGB captures often fail when handling poorly-lit or texture-deficient regions. Similarly, recovering scenes with scanning LiDAR sensors is also difficult due to their low angular sampling rate which makes recovering expansive real-world scenes difficult. Tackling these gaps, we introduce Gated Fields – a neural scene reconstruction method that utilizes active gated video sequences. To this end, we propose a neural rendering approach that seamlessly incorporates time-gated capture and illumination. Our method exploits the intrinsic depth cues in the gated videos, achieving precise and dense geometry reconstruction irrespective of ambient illumination conditions.
Paper
Gated Fields: Learning Scene Reconstruction from Gated Videos
Andrea Ramazzina*, Stefanie Walz*, Pragyan Dahal, Mario Bijelic, Felix Heide
CVPR 2024
Neural Gated Fields
The neural gated field approach is tailored for reconstructing scenes from gated videos using a neural field representation. Active gated slices, alongside a passive slice, capture the scene, integrating photometric cues and scene priors. Neural fields, such as those for ambient light, surface reflection, and shadow effects, are conditioned on spatial embedding, facilitating joint estimation of light and material properties. A physics-based model handles illumination and shadow modeling, employing a higher-order Gaussian function to compute illumination intensity. Shadow effects are directly estimated from the density field.
\[
\tilde{I}_{k}(\mathbf{r}) = \sum_{j=0}^{N} w_j \Big( \underbrace{\alpha_j \tilde{C}_{j} \psi_j |\mathbf{n}_j \cdot \omega_j | \iota_j}_{\substack{\text{Active} \\ \text{Component}}} +\underbrace{\Lambda_j}_{\substack{\text{Passive} \\ \text{Component}}} \Big) +\mathcal{D}_k
\]
During training, the model is supervised through various loss functions. Photometric loss ensures alignment between predicted and ground truth images, while volume density regularization and shadow estimation refine scene representation. Normals consistency and reflectance regularization ensure spatial coherence and accurate separation of scene components. These losses collectively constitute the total training loss, guiding optimization. Additionally, the approach integrates LiDAR rendering for enhanced depth and intensity estimation, further enriching scene reconstruction capabilities.
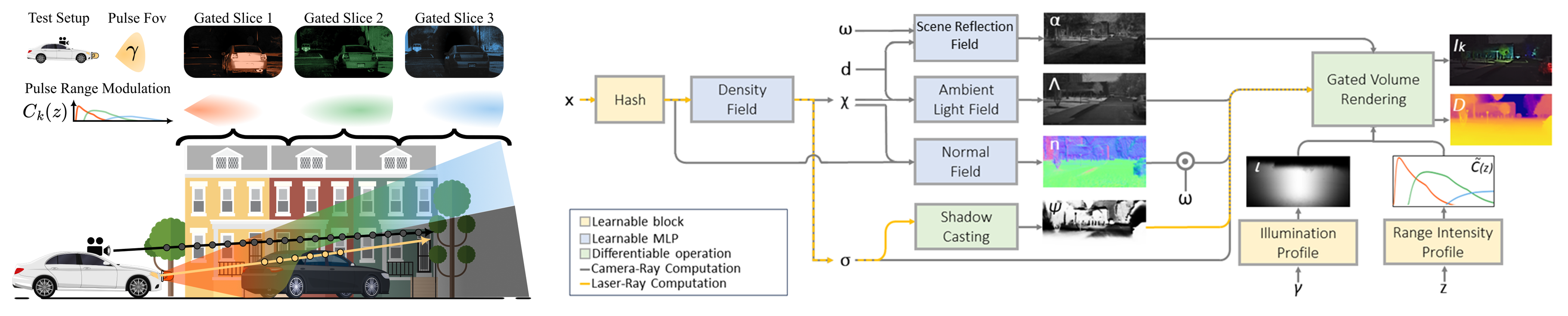
Left : Gated Image Formation and Bi-Directional Sampling. Top-row: Our test vehicle is equipped with a synchronized stereo camera setup and illuminator that flood-lits the scene with a light pulse and FoV $\gamma$. Using different gating profiles $C(z)$, we capture three slices with intensity visualised here in red, green and blue. Bottom-row: we show the ray sampling employed in our method, based on a bidirectional sampling strategy.
Right : For any point in space $\mathbf{x}$, we learn its volumetric density $\sigma$, normal $\mathbf{n}$, reflectance $\alpha$ and ambient lighting $\Lambda$ through four neural fields, conditioned on direction $\mathbf{d}$, incident laser light direction $\mathbf{\omega}$ and spatial embedding $\chi$. The illuminator light $\iota$ is represented by a physics-based model dependent on the displacement angle $\gamma$, while the gating imaging process is described by the range intensity profiles $\tilde{C}(z)$ using as input the camera-point-laser distance $z$
Shadow and Illumination ModelThe method models the illuminator’s light pulse as a cone of light with irradiance maximum at the cross-section center, gradually decreasing as it diverges. It uses a 2D higher-order Gaussian to represent illumination intensity. Instead of predicting shadow indicators directly, it estimates them using the density field. The illuminator origin and direction, obtained from the camera, are fine-tuned during training, along with other parameters like illuminator profile properties and gating parameters. Additionally, a general distance offset is optimized to compensate for internal signal processing delays. |
Novel Gating SettingsWe introduce a novel gated image formation model. The system employs synchronized stereo cameras and an illuminator emitting light pulses, allowing the capture of specific distance segments in the scene. Unlike previous models, this approach integrates shadow effects and self-calibrated parameter learning. The model formalizes range intensity profiles considering distance, time, and a parameter set, facilitating gated pixel value determination. |
Results: 2D Depth Estimation
The evaluation of Gated Fields’ depth synthesis quality for unseen camera poses relies on accumulated LiDAR point cloud data as ground truth, enabling unbiased evaluation up to 160 meters. Comparative analysis against nine depth estimation methods, including RGB-based and LiDAR-based approaches, highlights Gated Fields’ superior performance, particularly in night conditions. The limitations of RGB-based methods in low-light settings underscore the advantage of gated imaging’s ability to capture meaningful 3D representations consistently across lighting conditions.
Results: 3D Geometry Reconstruction
We evaluate the 3D scene reconstruction capabilities of Gated Fields using accumulated LiDAR point cloud data as ground truth. Employing voxelized occupancy grids, we compare against RGB and RGB-LiDAR fusion methods, computing metrics such as IoU, Precision, and Recall. Results show Gated Fields outperforming RGB baselines by an average of 15% in IoU. While RGB-LiDAR fusion methods partially enhance results, they struggle with finer surface details and low-light conditions. In contrast, Gated Fields leverage gated imaging, illumination, and depth cues for reconstructing finer geometries consistently across lighting conditions.

From a single video of gated captures, we reconstruct an accurate scene representation and render depth projections as accurate
as LiDAR scans, and we recover 3D geometry and normals at day and night.
Dataset
The dataset created in this study comprises 10 static sequences captured in diverse day and night conditions across North America. Equipped with a NIR gated stereo camera setup, RGB stereo camera, LiDAR sensor, and GNSS with IMU, the test vehicle records synchronized high-resolution images and depth data. Each gated camera operates at 1280×720 resolution and 120Hz, while the RGB cameras provide 12-bit HDR images at 1920×1080 resolution and 30Hz frame rate. LiDAR sensor data is aggregated to construct a dense ground truth pointcloud, refined using LIO-SAM for precise scene representation. With 2650 samples split into training, validation, and test sets, the dataset offers diverse scenes for scene reconstruction tasks, supported by visualizations and detailed data aggregation methods in the Supplementary Material.

Examples from our Gated Fields Dataset. We show RGB, gated image and accumulated LiDAR ground-truth depth.
Related Publications
[1] Stefanie Walz, Mario Bijelic, Andrea Ramazzina, Amanpreet Walia, Fahim Mannan and Felix Heide. Gated Stereo: Joint Depth Estimation from Gated and Wide-Baseline Active Stereo Cues The IEEE International Conference on Computer Vision (CVPR), 2023.
[2] Thomas Muller and Alex Evans and Christoph Schied and Alexander Keller, Instant Neural Graphics Primitives with a Multiresolution Hash Encoding, ACM Transactions on Graphics, 2022
[3] Turki, Haithem and Zhang, Jason Y and Ferroni, Francesco and Ramanan, Deva, SUDS: Scalable Urban Dynamic Scenes, Computer Vision and Pattern Recognition (CVPR), 2023
[4] Guo, Jianfei and Deng, Nianchen and Li, Xinyang and Bai, Yeqi and Shi, Botian and Wang, Chiyu and Ding, Chenjing and Wang, Dongliang and Li, Yikang, StreetSurf: Extending Multi-view Implicit Surface Reconstruction to Street Views, arXiv preprint arXiv:2306.04988, 2023